Jeff's UltraTechnology Blog
![]()
![]()
![]()
![]()
![]()
The Silicon Valley Forth Interest Group released the notes and videos from their Forth Day in November. I discovered that they had their video camera pointed at the speaker with only the bottom right corner of the video projector visible.
In the SVFIG mail list we heard that the slides from most presenters from Forth Day have now been posted at: http://www.forth.org/svfig/kk/11-2010.html
and that most of the videos can be found at: http://www.forth.org/svfig/videos/fd2010.html
We should expect those two pages to be merged together.
The nice thing about high definition video cameras is that one can put a 4x3 video at 1024x768 resolution in the left side and have a third of the scree left over to capture the presenter on video. One can then remaster it down to a slower frame rate and the lowest resolution that still shows what is on the computer display and being presented. This year there were presentions with big fonts in PowerPoint and presentations with big fonts in colorforth. Both were displayed on the video project for everyone.
Here is a jpeg image of a frame from an HD Video I shot of Chuck's 2006 FireSide Chat. Click on it once or twice to see it in full resolution.

I assumed that that is what SVFIG was going to record to video. This was something I did for years and was happy to let them do instead. But when I looked at the videos for this year I realized that they had filtered out all the video from the video. They had video of the presenter but not the video presented by the presenters.
SVFIG then collected the "Slides" from the people in PDF format so they could offer what some people presented on video to them on their web site. But because they didn't video the video they filtered out all the coloforth presentations and only passed on PDF slides to people instead.
I went ahead and made a few slides from the colorforth screens I used. It isn't as good as the live video where you see what the editor, compiler, simulator, and ide do keystroke by keystroke. But it is better than just a talking head talking about video that you can't see.
I guess I have odd expectations of what might interest people in the Forth Interest Group. The PDF file that Greg Bailey did was generated by a tiny amount of Forth code. I would think people interested in Forth would be interested in the tiny amount of Forth code needed to generate a PDF file. But it seems that they would need the Forth code in PDF format before they could see it at all the colorforth video output was not recorded at this year's Forth Day.
There were about forty people who attended the Silicon Valley Forth Interest Group's Forth Day this year. It was fun seeing friends and hearing about what other people are doing with Forth. It is always nice when people can get together to discuss Forth without anyone objecting to their use of Forth or wanting to take up their time telling them that they should be using something else instead.
I found it interesting that there were more reports on Forth in hardware and software than about Forth software for conventional hardware. In 2009 Leon Wagner of FORTH Inc. gave a presentation where he built a RISC CPU for a FPGA and used SwiftX to compile Forth code for it. This year FORTH Inc. had Brad Eckert show a Forth CPU and generate Forth code for it. Along with Green Array Chips presentations there were other presentations on Forth in hardware and software.
I enjoyed Dr. Montvelishsky's presentation on a 3D steroscopic machine vision application for a robot. It was similar to the one we did for BMW research. The problem with the previous system was that it consumed too much power. They liked the version that could run the whole thing from a small solar cell.
Green Array Chips President Greg Bailey told of plans for 2011 and plans for on-chip flash and/or large on-chip SRAM blocks. He provided some background and insight into the company's strategy.,
I showed some simple F18 processor code examples running in software simulation and on hardware using the Interactive Development Environment. Softsim is available now in the public release of ArrayForth and the IDE will be provided before chips and development boards are shipped to customers. Differences between colorforth and more conventional Forth were shown, differences between Pentium colorforth and colorforth code for targeted Green Array Chips were shown. Differences between software simulation and the Interacitve Development Environment were show.
In Pentium colorforth N FOR NEXT performs N interations and exits and removes the index from the return stack when it reaches zero. On the target colorforth code for F18 processors FOR NEXT counts down past zero so performs N+1 iterations of a loop. The word ZIF which is a sort of forward NEXT so that FOR NEXT loops can perform N interations when that is desired. NEXT takes an address argument left by FOR or BEGIN and resolves the NEXT branch when it is compiled. ZIF compiles an unresolved forward NEXT which is resolved by a THEN.
The words IF and -IF and the associated UNTIL and -UNTIL are also different on Pentium colorforth than in target colorforth. On the Pentium version they use actual Pentium status flag rather than the contents of the top of the stack. So in target colorforth you can say:
... IFor
... 0 OR IFand IF will do the same thing in either case, it will test if the top of stack is zero and branch if it is zero. Exclusive Or-ing whatever was on the stack with zero will make no difference except that it will take up time, program space, and use power. Furthermore IF which tests for the top of the stack being zero or -IF which tests if the top of the stack has the sign-bit set can be nested as deeply as desired. On the other hand Pentium colorforth has an IF that tests the zero flag in the Pentium processor. The way it is used is:
... 0 OR DROP IFwhere whatever was on the stack is exclusive-or-ed with zero and then that flag droped from the stack. This sequence is for an IF that uses the Pentium flag and not what is actually on the stack. So it isn't nestable in the same way as the target code and is used in a different way.
In Pentium colorforth variables are created as variables when they are defined in the editor.In colorforth variables are initialized to zero when created in the editor. In traditional Forth variables were initialized when they were compiled but in ANS Forth they are not. Variables are normally initialized somewhere and in colorforth are often initialized in a sequence of yellow interpreted code after the place where they are defined when the compiler is running. If they have a yellow sequence they will be initialized when the code is compiled. Sometimes variables are initialized in compiled code executed by the application.
In colorforth the variables in the source are actually variables created and tagged by the editor. They are initialized by the compiler or by an application. Because they are live their value, in the source code, will reflect the latest change to their value that has happened.
While a program is running or after it has stopped the contents of the variables in the source code reflect the last change the application made to them because the variables in the source are the application variables. Variables are live in the source code. Numbers and variables in a program are actually numbers and variables in the source itself and make for more powerful programming tools. By itself live variables is a very powerful debugging tool built in at a very low level in the system.
One of the innovations in colorforth is that variables are live. If you look at the source code for a block, edit it or list it, then have a program change the contents of that variable or if you change the contents of that variable on the command line you will see the contents of the variable change on the screen. You don't have to open a special watch window, you don't have to refresh the editor view, a previously edited or listed display of the source code will change on the screen as its contents change in the background.
I would not expect people who have never tried them to easily appreciate how powerful and productive they can be. I have just touched on a couple aspects of these things. The implications of what you can do with them are profound.
It is a powerful thing to be able to do all these things at edit time, at compile time, and at runtime with no effort. Many people are not using Forth tools at edit time so they simply cannot use these features of Forth systems. I can imagine some of it being done in other languages. One can think of it as simply a program treating its source code as data. But it does use database and spreadsheet like features way below the level of files and uses them to contain and manipulate source so that more can be done with it in all time phases.
Variables work a certain way in Pentium colorforth but are not used the same way in the target code for the f18 processors.
Many Forth provide a way to view the stack or give the user a default view that includes a stack view. Some Forth provide a way to specify that you want to watch a variable and see a live view of its contents. They may let you specify a variable to watch or to place a variable's address into a memory watch window. But that is not as powerful as having all variable automatically do that in the editor while giving the abstract source code view.
Like blue words in the source the live variables in the source are an example of how Forth spans more of the time dimension than some language by letting the user specify edit time, compile time, or runtime and do editing and compiling in applications at runtime as well. Live variable in the editor and blue words in Forth are examples of expanding the power of Forth at edit time.
Wil Baden provided excellent examples of being able to cut and paste Forth code in an editor to create macros in Forth that editor can execute by doing a call-back to Forth. In colorforth this whole process is made as simple as possible by saying that blue words execute when the editor encouters them. The first thing I did in my demonstration of colorforth was to turn the word SEEB from white to yellow. This word means "See blue words."
I explained that even though they are not visible on the screen when SEEB is just a comment in white at boot I still see them in my mind because I know a blue word had to perform the return or reverse return or tab that I see there in the colorforth editor display. But when SEEB is executed on boot you actually see the blue cr or -cr or tab on the screen along with the effect that executing it caused. These blue words make spread-sheet and other on-screen macro execution possible and support the use of edited blocks with blue words as templates for other operations.
I showed the Pentium colorforth tools to convert to or from ASCII and to HTML as well. I showed various I/O drivers and utilities such as the ADUIT tool for source code management. The ADUIT utility lets one see blocks that have changed relative to a previous release and let one toggle the block display between the two versions to highlight the change. Like other things in colorforth you can feel that it uses different parts of your brain than a less visual tool which relies on more use of symbol processing in the brain of the user.
I showed the powerful set of tools that do things that are very difficult with ASCII source code in files spread out over multiple directories, disks, or networks. It should be easy to "find" words in a Forth dictionary after they are compiled but when working with source it is very useful to be able to search all sources for all definitions of a given word or all places where it is used or to search for where literal numbers are used anywhere in any source. These things are easy, simple, trival and fast when Forth can do more at edit time. For many people these things are so difficult that they don't do them at all and don't even know what they are missing. One might say that a side effect of being forced to use ASCII files as containers for source are that you don't have a lot of useful and powerful forth tools to make the work easier.
I showed how Pentium colorforth displays the numeric value of a word as it is being typed in to the command line before it is executed. I also showed how it displays what is on the stack on the left side of the command line. If you start with nothing on the stack and type "DROP DROP DROP" then enter "1 2 3 4" you will see that you have a "4" on the stack. You have the word "C" to clear the data stack and set the stack pointer to its default value.
The target colorforth offers the word "unext" which works like NEXT but branches back to slot-0 of the same instruction word in which it runs. It discards any address argument provided by FOR or BEGIN so that it can use the same syntax as NEXT. Instead of a five nanosecond memory operation like NEXT it is a two nanosecond operation so one can adjust the timing of loop timed by unext in two nanosecond intervals. A no-operation or "nop" instruction is specified with a period. Since it is in the stack or alu class of instruction it executes in about one and a half nanoseconds. So with two nanosecond changes and one and half nanosecond changes one can tweak timed operations to about half a nanosecond. Pentium colorforth does not have the equivalent of a unext operation but perhaps it could be added by using a repeat-previous instruction and count down instruction.
In addition to the simple bit-bang pin-toggle loop examples shown the use of I/O and math rouintes in ROM were shown. One can use ROM code to read from the SPI flash, read synchronous, asynchronous, or one-wire asynchronous signals. Other ROM code includes multiplies, fractional math, left and right shifts, triangle trigonometry, polynomial approximation, taps for fir and iir filters, table interpolation, pwm output and more. The software simulator compiles the ROM code along with any user application code and provides a way to get hands-on exerience with using these ROM functions and see some well coded examples of machineForth. With very limited on-chip RAM on each node it is important to understand what the ROM code offers to let programs in RAM be smaller and do more.
At the end of my presentation I ran a little program that fit on one node that copied itself in two dimenstions and carried a bitmap with 144 pixels. On each node it would then index into the two dimensional bitmap and decide if it should stay on or go to sleep and in doing so leave a pixel on or off in the softsim display. I just wanted to see I could write that fairly quickly and get it to fit on single node. I joked that I wanted to show Forth on the simulated chip.

At the end of Chuck's Fireside Chat I presented him with a framed wafer of Forth chips to go on his home or office wall. I has about five thousand clusters of twenty-four Forth processors or about one hundred and twenty thousand Forth processors on one piece of silicon. With thirty-two, forty, or one hundred and forty-four processors per cluster the number of clusters goes down but the total number of processors on each wafer goes up. Ideally if one wanted to use wafer scale chips one would want surface mount flip-chip pads for I/O and if there were clusters they should be connected to one another on-chip using parallel connections like inside of clusters.


SVFIG will put videos of all the presentations on their site at some time in the future.
There are few topics where people make arguments from a position where logic will be of little help. On these topics dialog usually can't go anywhere but to name calling or hate speech. When in a discussion what does one say to a comment like the one made by Christine O'Donnell, "You know what, evolution is a myth. Why aren't monkeys still evolving into humans?" Richard Dawkins said, "spectarularly stupid" but that doesn't forward dialog.
One of those topics is Chuck Moore's colorforth. I understand it is different, very different than the things in computer science that you know or that you do every day. It is natural that you might have no interest or want to deal with something so alien to you.
It is natural that there are people who use a different language than you, you would be an alien in their community. They might look differently, have different tastes in food or style and different rules for proper social behavior. Dealing with an intense exposure to such alien culture is difficult for many people but a bigger part of the modern world. Still most people never do get much exposure to the real details of other cultures.
In any situation the dominant culture will get most of the exposure, this is sort of the definition of a dominant culture. You can't avoid exposure to the dominate culture and it is easy for everyone for the most part to see the parts of it that they are suppose to see as that is part of the culture as well as not see things that they are not suppose to see. Part of culture is to see things the way the culture says they should be seen. That is always part of the culture.
It is easier to understand when a minority culture hates a majority culture that wants them to maintain a low profile or assimalte until they are not a minority culture. Still minorty cultures for the most part don't hate. Most to the hate is a consequence of how some people of the people respond to and focus on the hateful chatacterization of the minority culture.
A minority is likely to have a strong cultural indentiy but also see itself as a part of the larger dominant culture. The dominant culture on the other hand may consider minority culture as alien and not really part of their culture.
But if you are part of a minority culture where almost everything is about the dominant culture there are some special problems that you will have. Your culture can't get the exposure that really define it because what is exposed to everyone is the dominant culture. Often people in a minority culture have a serious concern that the little exposure their culture gets in the dominant culture does not represent them well, has to be limited by definition, and may be represented only in hateful caricature.
People who want to deal with the problems of the a majority culture treating their minority culture badly because the only exposure their culture is given is hateful caricature have some special problems. If you say that a solution is for the majority culture to get more exposure to the real details of the minority culture this goes against the very tennants of the majority culture and the counter argument will be that the minority culture needs more indoctrination and assimilation into the majority culture. This is the problem the minority culture needs to reduce but any attempt to get more exposure that a minority culture thinks represents them properly so that they can be treated fairly is likely to simply produce more hateful caricature of their culture.
If the dominant culture believes that the earth is six thousand years old and bases their world view on a group of facts associated with that fact a minority culture that has a world view based on history and science will have all the cultural problems that happen when a majority culture wants a minority culture to assimalate and blend in. They have lots of proof that ideas like evolution are wrong. Monkeys don't change to humans at the zoo.
What can you say when that is the dominant culture? Promoting science instead of God may be seen as a very bad thing and characterized in a hateful way. If a minority group makes any effort to get the majority culture to address the problem they see through education the response they are likely to get is that there is a problem to be addressed in the educational system that led to an assualt on God and that the clear solution is to get the science out of the educational system and replace it with scripture instead.
My use of the word "God" may make the argument seem very culturally specific and will most likely cause some readers to feel insulted or that their own culture has been assaulted. I appologize for hurting anyones feelings and wish them no harm. I ask anyone who feels any of that to go back and reread the last paragraph but substitute the best words for you to be the opposite of the words "God" "science" "scripture" "education" and reread the paragraph.
For a Christian person who might have felt the tiniest bit of resentment or disagreement with that paragraph they should picture if they were living in a dominanlty Muslim culture based on whatever exposure they have had to whatever they think that culture is like.
Promoting Christianity instead of Islam may be seen as a very bad thing and characterized in a hateful way. If a minority group makes any effort to get the majority culture to address the problem they see through education the response they are likely to get is that there is a problem to be addressed in the educational system that led to an assualt on Islam and that the clear solution is to get all exposure to Christianity out of the educational system and replace it with scripture in instead.
Perhaps you can't relate to either of these cases and want a rather odd variation. I have been doing almost all of my computer programming in the Forth language for the last twenty-five years. Any language creates cultural boundries. I live in a world where there is a dominat programming culture. People cannot avoid exposure to it. They cannnot help but seeing it and all the books all the classes in the educational system are about it. Most of the blogs and websites and discussions are about it.
So I belong to a minority culture where we get very little exposure and the little we do get is mostly hateful caricature. And this hateful caricature is the only exposure in the educational system or the business or hobby computing culture as well. Having said that I am willing to repeat what is common knowledge and suppose to be taught about the minority culture of Forth.
Forth isn't really a programming language at all, it is a religion. Forth is a write only language. Forth's very limited value was only in the past on very small machines. Forth had some value thirty years ago but then C won and Forth died. Forth is a joke. Forth is a cult. There has never been a single decent program in Forth. Forth stinks.
Those are all statements taken from popular magazine articles and columns or that appear again and again in blogs and newsgroup discussions. They are the things the dominant culture say about us and teaches about us. Part of the culture is that this is what people are suppose to say about Forth.
These things seem like hateful caricatures to me. but don't seem out of place in the view of the dominant culture. Every one of those statements are as wrong as they could be and are meant to protect one culture from mixing with another, understanding, or being understood by another.
The problem is no different than the same problem of a minority culture in a majority culture in many other contexts. If you try to address the problem that you think this is an untrue and unfair if not hateful representation of your community and that it just encourages unfair or hateful treatment the effort is seen as an assault on the majority culture which requires that the amount of hateful caricature and dominant cultural indoctrination needs to be increased.
What can you say when the arguments presented are monumentally stupid and hateful? My response has usually been to go away and provide some explanations of what we really do, documentation, code walk throughs, tutorials, benchmarks, essays, interviews, transcripts, and videos that I think represent out culture accurately. Consider that the only exposure the dominate culture gives is that we are dead, religous extremists, or cultists. And in the dominant culture those are about the worst possible things that people can be.
But no matter what you do people argue that they went to wikipedia or google and everything said the same terrible stuff about what your subculture does. They don't want to listed to what we say we do.
You can't avoid exposure to the dominant culture. If you try to get what you think is the tiniest bit of accurate exposure to your minority culture no matter how small may be seen as a major assault on the majority culture that requires a major response. This is suppose to be less of a problem in the American "melting pot" culture. But as is always the case many things are supposee to be diluted until there is no longer any trace of taste of them in the mix because they are just too alien to be accepted within the majority culture.
When the minority culture wants to get what they think is a little fair exposure so that they can be treated fairly rather than in some hateful way the response is likely to be that they need to go away and get more indoctrination into the majority culture until it is no longer a problem. When I try to tell people what it is that I and other Forth programmers around me actually I the dominant culture requires that many more examples of a hateful caricature be produced in response.
What's ironic is that a dominant culture is required to provide more examples of their view a minority culture than that minority culture is suppose to provide of themselves. In the case of my programming culture one of the favorite facts used to prove that the only characturizations that are correct about us are the ones most easily available. In fact there simply is no and had never been any information available to learn anything about Forth at school, at the bookstore, or on the Internet than what the dominant culture provides. And I quoted from that previously.
But as I said before often when confronted by a number of people who all felt that the only characturization that should be provided of what I do or what I and people around me have done should be the sort of thing I quoted above from magazine columns about Forth.
I have told people that there was a lot of actual information about what we really do or really did that got put out in front of the public. Most of what is out there and easy to find if from the C programming culture and which we do not thing characturizes us fairly or accurately. And though much less than the information available about the dominant C language computing culture we have actually put a lot of information out there so that anyone who want to actually understand what it is that we really do can do so.
When people have made it clear that their only exposure to what we do or have done has been hateful caricature I have tried to direct them to the things we have made public about what we were doing. Here is a short history of information we thought characterized what we do and did.
Things from the 80s: cmForth the public domain 6k optimizing native code metacompiler for Novix. Dr. Ting's Footsteps in an Empty Valley. The first dozen issues of More on Forth Engines. Documentation from Novix and Harris. The cmForth port to RTX. The development of the 32-bit 100MHz Shboom. The development of machineForth. Papers on a number of forms of parallel Forth. Presentations on the start of VLSI CAD tool development in Forth. ANS Forth started and was offered details of machineForth for consideration. The ShBoom manual.
Things from the 90s: Chuck's presentations on okad, MuP21, machineForth systems. Full machineForth systems. A megabyte of html describing ANS systems written in machineForth. Dr. Ting and Chuck's VLSI Hacker's Forth toolkit. The OK386 manual. FORML presentations on the evolution of machineForth and the introductions of parallel programming with benchmarks. Presentations on how to program GUI accelerators on Forth chips. ANS Forth finished. Presentations and write up of various applications. The documentation on iTV's 4OS and I21 chip, web browser, email, web host, and dozen web protocols. Forth Linda. Forth DSM. F*F. Dr. Montvelishsky's example of CSP in Forth similar to Occam semantics as a learning tool that runs on a PC using Forth multitasking to learn parallel programming. Dr. Montvelishsky's cordic and math functions in machine Forth that were 50 times faster than Intel's versions at the time. Explanations of colorforth. John Rible publishes college classroom designs and give classes in designing processors with examples from a tiny-RISC and a Forth designs in VHDL. The design class videos and transcripts are made available to the public. Twenty more issues of More on Forth Engines. Dr. Ting puts some VHDL Forth chip designs into the public domain. The nine gigabytes of video presentations and html transcripts hosted at the UltraTechnology site. The workstation in a mouse project.
Things from 2000: Chuck's presentations on 25x. Presentations on how aha worked. More issues of More on Forth Engines. How the public release of the stand-alone colorforth came about. How this version of colorforth worked. Presentations on how OKAD 2 works. Gigabytes of videos of presentations and programming tutorials hosted at UltraTechnology on programming of MISC. Dr. Ting publishes new manuals and presentations on his P16, P24, P24X, P32, and P64 processor designs. Chuck creates his colorforth web site. I add a blog. Presentations about early work at Async Array Devices and how it became IntellaSys. Explanation of the use of various CAD software. Presentations on new features in machineForth and hardware to improve application performance. Presentations on programming in colorforth and VentureForth. Presentations by a dozen Intellasys employees. Explanations and code reviews for a dozen applications and tutorials. Many details of many projects presented to SVFIG or EuroForth or through the IntellaSys website or UltraTechnology. Presentations of Forth soft radio are given. Reports on expensive comparisons between OKAD and convention tools were given. IntellaSys releases VentureForth with compiler, simulator, visualization tools, and a drag and drop framework. SEAforth24 and SEAForth40 designs are provided with detailed manuals. Presentations on ROM code details with lots of examples and code explanations for SPI packet boot, asynchronous autobaud packet boot, syncrhonous autobaud packet boot, 1-wire packet boot, external memory interfaces, analog I/O, interprocess communications, forward and reverse port pumps, math routines, message routing, and Forthlets are given. Methods and example of data-flow analysis and data-flow algebra are given. Arrangements are made for FIG to get free or discount chips from the first IntellaSys wafers. The hearing enhancement project and stereo vision projects are presented. IntellaSys does wafer production runs and describes the details. Explanations for what should happen when IntellaSys went away were given.
Things from 2010: Dr. Ting puts more chip designs into the public domain. Chuck adds a blog. Green arrays forms and gives several presentations. Many code examples are shown again but in improved forms. Green Array Chips GA4, GA32, GA40, and GA144 multi-core parallel Forth chip design documenation is provided. Demonstrations of colorforth softsim and IDE are given. A comparison of the performance of various modern Forth compilers on specific compiling examples and an OKAD like applicaiton are presented and published. More presentations to be provided by various people at the 2010 Silicon Valley Forth Interest Group Forth Day event.
Lots of the stuff I found interesting was never public information and I probably forgot some important things that were made public. In hindsight I think UltraTechnology was far too open and honest about what it was doing. The idea of $5 educational networked Personal Computers with workstation performance that could download Forth programs embeded in video broadcasts and mix input video with computer generated video was seen as an assualt on the dominant culture. It seemed that I had not appreciated the cultural acceptance of the digital divide. But people in some governments and militaries were watching closely and didn't need us to be so public to show interest and follow through. The competition was watching as was in the parking lot at ITV taking pictures of our meetings so they didn't need so much public information either. There were people breaking in and trying to break in to servers to learn about what we were doing. There was interest out there. But the way we are depicted in the dominant popular culture is quite different than what we say about what we were doing.
In retrospect I have wasted too much time trying to use logic to help the Forth haters understand what we do or correct the misreprentation by the competition. But there is that univeral cultural problem to deal with. Better I think to just ignore the haters and people with the spectacularly stupid arguments. Trying to deal directly with them is a waste of time. Now if I can just follow my own advice. It is probably better to just go off and work on some code, documentation, or on the next presentation.
I am suppose to present for the Silicon Valley Forth Interest Group again in a couple of weeks. It is fun to see old friends and hear about what other people are actually doing with Forth. I no longer bother to make videos, write transcriplts, and post it all on my site. But SVFIG does make and post videos of Forth Day presentations so there is more information available to more people about what this minority culture is really about and really like.
What's funny is that as soon as we step outside of a culture that understands the sort of Forth word we do we find people who react like they have heard we have been pursuading people to send us all their money and begin worshiping the devil.
To be honest I don't care whether you would want to do the kind of work we do or not. It would just be nice if the dominant culture could be a little gracious and provide us with an occasional opporutinity to say something about what we do without some group from the dominant culture needing to put on hoods. If they were just willing to let us provide a little description of what we that we think is accurate and fair without feeling a need to provide more counter characterization of what we do to defend and promote the dominant culture.
It used to amaze me that you could give someone the foor for hours to explain how the dominant culture sees software, something you cannot help getting exposed to anyway, at a Forth Interest Group meeting but when the inventor of Forth takes the floor for one hour in the year and begins to explain what he does in a way that he thinks is fair that the previous speaker could interrupt him preventing him from talking to shout things like, "That's not the way a C programmer would approach that ...."
What amazed me was that dominant culture was not willing to give up the floor for even an hour a year in a small group of people gathered to hear about Forth without bringing things to a hault because we obviously needed more indoctrination into the view of the dominant culture and be told again that that is not how C programmers see things. It seemed inappropriate to me but part of the dominant culture is that you are not suppose to see that as inappropariate. It is the responsibility of the dominant culture to indoctrinate minority cultures and get them to assimalate into the dominanat culture. Ok. You can gather to disucuss Forth once a year, but the floor must be given to indoctrination in C instead of Forth lest it get out of hand. But I do understand that this is just a univeral aspect of culture.
Newsgroups and chatrooms have the same problem of course. Discussions of Forth are allowed as long most discussions are about writing C or Perl or Java or MD5 or shells or using operating systems written in C or editors written in anything but Forth or topics where they never even mention Forth. It is the responsibility of the dominant culture to keep things fair and balanced.
Discussions about things like colorforth will solicit demands that you go out and use other languages instead. You don't want to use that, I don't want to stop using myForth. I don't want our customers to stop using ourForth. I don't want to stop using C. I don't want to stop using Perl and Lua. Stop doing that. Go out and learn Perl instead. Go out and learn C instead. No one should do that. Go out and learn Haskell instead. Go out and learn Python instead.
When the subject that some people do colorforth or different ideas comes up some people get very intolerant and don't think people should even be exposed to something that alien. So even if it only gets discussed once a year and Chuck Moore gives a presentation where it will come up then some people will be rather intolerant of letting people who know about the subject described it without the majority of people each giving a more dominant culture point of view and to limit how much minority information will be tolerated. But again it is just a case that dominant culture cannot have very much tolerance towards minority cultural views getting exposure. Cultural stereotypes make things simpler and it is the responsibility of the dominant culture to make sure that its point of view always gets to dominate.
I gave a short presentation today for the Silicon Valley ForthInterest Group. I said that there were several projects I could give presentations on including reporting on couple cute pieces of equipment I could review. I had wanted to look into doing some USB client code. I started by reading about USB and then got a couple devices to help me explore the problem.
I have a tiny litte Beagle Board USB analyzer. It has three USB ports. One you connect to your PC as the user interace and then is has two other ports you put between a USb host and USB client. It provides different views of USB messages at a sort of high level. I also got a tiny logic analyzer that has one chip with a USB connection on one side and 17 aligator clips on the other, one ground and 16 probes. It can capture a meg or so at up up to 16 or 24MHz. With these views I was able to see more about what was going on with USB.
My first analysis suggested that I should implement low level code first to handle resets, bits and packets. I wanted to try to get that on one node in under 64 words of code. The higher level protocol could then be handled by more nodes with access to flash memory to be able to deal with the larger amount of detail at the protocol level. I got the low level stuff mostly working but found the overly simple hardware interace I had set up produced glitches when I switched from bit read to bit right. I got some help from a hardware engineer on what should be a better external hardware connection to USB. Because I had a voltage level converter circuit in the simple design I did the signals looked good on one side of the converter but not the other. I will go back and do more work on it sometime.
I found some cute hardware; RSDV HS MMC. Those are reduced-size dual-voltage High-Speed Multi-Media cards. They work at 1.8v or 3.3v. They are about half the size of a regular MMC. They support SPI at 25MHz. The high-speed ones also have a mode where they use an eight bit data bus instead of a single pin. They can run up to 52MHz and 416MBPS. I want to hook one up in SPI mode so I can have removable flash, usable on a PC also, with gigabyte capacity. I also want to find out whether I can put several of them on a Green Array Chips external parallel bus and drive control signals on them in parallel. It could be used as a very raid solid state hard disk with very high performance. The literature also says that they can be written and erased very quickly for flash devices. I haven't done much with that project yet either.
I showed them the Green Array Chips public colorforth release that has the target compiler and softsim program. I showed them the user interface and a couple of programs that made an interesting visual displays on the interface as you saw the interaction of the 144 core running, communicating, and sleeping. Someone asked about how it worked as both a stand-along boot program and OS on some PC and also ran on Windows on a much wider range of machines and what it put on a PC when you installed it. I mentioned that Green Array Chips had short videos showing how to download and install it and what you got. We also started with some simple stuff showing the user interface, editor and softsim to help people get started.
I showed a version of colorforth with the Interactive Development Environment. I always change my ideas about what to show after I watch other people's presentations. So I pointed out how the softsim interace and the IDE both do the same sorts of things we saw in other presentations. They provide ways to see what is on the stacks and in memory. In softsim you can move a 4x8 node window around to see the most important registers in each of those processors in another area of the display, how the disassembly window worked and could be moved around and how you single step or go or control how many steps are taken before each update of the visual display.
I has showed the IDE before and said it would not doubt be shown again before people got real chips or chips on development boards and wanted to try the IDE on them. There was question or two about the internals, not on the PC but on the target chip and I showed how it set up a path for messages to go from an entry point on the chip accross other processors by executing code on their ports copying messages from one port to another. That way they don't effect the memories or most of the stacks on the nodes that help when you talk to a given node and deal with its stacks and memory in an interactive fashion.
I mentioned that Green Array Chips had been taking orders and the current retail price is $10 for 144 processors or just under 7 cents per computer in the cluster. That also works out to a maximum code execution rate of better than one hundred Forth MIPS per cent of retail cost.
I also mentioned the $1.99 Linux computers that had been mentioned in the SVFIG mail list. These are odd machines. The only I/O they have is USB. If you plug them into a computer with USB but that doesn't boot from a USB port they are just treated as USB Flash sticks. $1.99 USB Flash sticks are not anything too special. In fact there were both $1.99 and $2.99 models where from what I gathered from a brief exposure is that the $1.99 sticks don't have much Flash memory, 64MB or something. But if you plug them into a PC with USB BOOT and boot them up it boots up a Linux system running on the stick and using the PC as a peripheral mostly. The Linux on the stick lets you read/write the PC's hard disk, keyboard, mouse, and screen. It comes with a bunch of tools including a browser and a version of Lua all running on the computer controlling your PC, the USB computer on a stick.
The whole idea seemed similar to John Harbold's presentation on porting gforth to ECOS under a Linux from a USB flash stick. His presentation was about stuff I know next to nothing about. I hadn't tried any of these Linux Computers on a stick as I had been very busy recently. But I brought a box of them into the FIG meeting and gave them away to people who wanted to play with them. Maybe someone will give a report on what they did with them. Maybe someone will port gForth or some other Forth.
I also wanted to see if you could bypass the Windows security, short of encryped files on a PC with USB Boot. Since the idea is that when you boot in Linux on the stick the hard disk on the PC is just a peripheral to your system and you don't have to go through any password security to boot Windows on the machine. So it might be useful to rescue PCs with health problems or with forgotten passwords. Some people know a lot about Windows and Linux and might make good use of these $1.99 Linux computers.
I also did a very fast review of benchmarks I had done to test the performance of Modern Forth Compilers. I explained what I had tested and why and showed the results very quickly. There were some questions about why the results looked like they did.
I said that 353 posts to usenet thread about dictionary hashing options in Forth showed me that many people were interested in how Forth compiler performance could be improved. The reason that so many of the popular modern Forth compilers used hash functions in dictionary searches was to improve their performance.
Before I began a very brief presentation on benchmarking some modern Forth compilers I said,"First let me say that there is not just one way of doing Forth properly. For instance in Dr. Ting's presentation today on eForth for his custom 32-bit processor it is very hard for me to picture any more efficient way to make all the processors he has and test and debug both new hardware and software than the way he described of using eForth.
I said I had been told that modern Forth compilers no longer used the forty year old Forth compiler loop. I will still have to ask again about that on usenet since I still think that most still do use that forty year old loop. I know colorforth and aha don't but that's not most modern Forth compilers.
The loop I was talking about is the one described on page 28 of the Forth Programmer's Handbook. That pages shows the whole classic Interpret/Compile loop used for the last forty years by most Forth and I had been talking about its compile loop in compile mode.
Parse source for the next Forth word.
Search the dictionary for that word.
If found check if it is immediate.
If immediate execute it.
If not-immediate compile it.
If not found in the dictionary try to interpret it as a number in the current number base.
If it is a number compile it as a literal.
If it not a number it is an error.
I am pretty sure that that is still how most Forth compilers work. I realize that the phrase "compile it" has different technical meanings depending on the type of threading or code optimizer the compiler uses. Most modern Forth use subrouinte threading with inlined native code and other native code optimzation but we still use the term compile a Forth word and even have an ANS word to make the meaning portable COMPILE, (compile-comma).
I was told that I was out-of-touch with Modern Forth compilers because I questioned that all compiles take place before you can take your finger off the return key, meet some new 1/4-second compile rule, or are all *instantaneous* as my experience is that they are not like that. Maybe if you are just still doing 1980 sized applications in Forth on your 2010 PC you find your compiles are faster than mine. But to me whatever the term Modern Forth is suppose to mean it should mean something today other than still compiling nothing larger than what we did on the Apple II in 1980.
To see just how out-of-touch I ran some benchmarks against a dozen Forth that I have seen advocated on usenet in the recent past. I downloaded them from the Internet, installed them, ran a few benchmarks, and put the results on a web page.
The people at SVFIG agreed that because Forth applications may make extensive use of the Forth compiler in that compiler performance itself was important there. The 353 usenet posts to the thread "What are my options for dictionary hashing?" in comp.lang.forth this month showed how many people there are concerned about getting good compiler dictionary search performance and fast compilation.
I was pleased to see that when I installed a version of Win32Forth on my machine that it had a Forth kernel compile the rest of the Windows Forth system. I had no expectations that its compilation was going to *instantaneous* as claimed for some Forth systems. Nor did I expect it to meet the new mythical 1/4-second compile time rule claimed for some Forth systems. It wasn't and didn't.
At least in that sense I wasn't too out-of-touch with modern Forth compilers as has been said on usenet. People often claim that Forth compilers are small compared to many other things so compiling one should be a lot faster than a serious modern application. On my 2GHz PC it only took 16 seconds.
You have to very slow hands to not be able to get your finger off the Enter key before the compiler is finished as is claimed for other Forth systems. 16 seconds may not be a long time to compile a fairly small and modest application but it surely is not instantaneous, faster than a single keystroke, or even close to the mythical 1/4-second compile rule. In fact it was sort of what I was expecting given how long it took ten years ago.
Maybe I was a little out-of-touch with modern Forth compilers and their performance at what they do. I wasn't expecting all the results I got. Some things were faster than I expected and some were slower.
I wasn't too surprised that the portable Forth written in "C" was one of the slowest but not the slowest thing I tested. I was a bit surprised that some of the Forth I tested and see advocated so often were a hundred or a thousand times slower than others.
I only downloaded, installed, and benchmarked systems I had seen being advocated on usenet within the recent past. I wanted to be objective and not make any value judgements before or durring testing. But I was only willing to spend an hour or so downloading and installing each system. I included eleven systems in the less demanding tests.
If your Forth system is there and I was not able to download it and get anything to run on it please forgive me. If your Forth system made it into the test then good for you. If you are not happy with the results your Forth system got in the benchmarks then it is up to you to make it better and it is not my fault. All I did was look, measure, and report.
One result of all this was that it made me want to rethink aha and work on an aha 2. I didn't include aha in the main benchmarks because they were all run on the PC I am using now. It has a 2GHz AMD Turion64 processor and aha just runs on F21 with 7 to 25 MHz DRAM and 50MHz SRAM so it isn't really fair to make it run in a race against the 2GHz class of machine. I did include it anyway in a couple of extra lists to show that the approach does have promise for improving compiler performance.
For the last decade the modern PC Forth I have used at work are colorforth and SwiftForth from Forth Inc. and I have used them for different purposes so I have never bothered to do any performance comparisons even on those. I wrote the original VentureForth system for target compiling to IntellaSys chips from a PC and it was run under SwiftForth, gForth, and VFX Forth but was not a compiler for the PC itself. I worked with aha but it was only for the F21.
I suppose I had listened to some estimates that people in comp.lang.forth had given for the various PC Forth system's comparative performance levels but had not ever tested anything or even seen any actual tests that anyone else had ever made. And it turns out that I was a little out-of-touch with the performance of Modern Forth Compilers for my PC. My guess is that you probably are too.
You were not as out-of-touch as me if you can look at the benchmark results and say, "That is exactly what I would have expected." All I could say was that it was sort of what I expected. The exact results and order of the participants on all three tests did surprise me.
I was asked how aha achieved 0.000101 nanoseconds per ASCII character in the comment character per second compile test. I explained that the aha editor puts a tag on comments like other variations of colorforth but does use the Shannon-encoded characters like Chuck's Pentium colorforth. I explained that ANS demoted the use of counted strings because they wanted to reduce conflicts between code that uses a count and address on the stack and code that uses an address that points to the count of a counted string. I explained that I promoted counted everything, not just strings, in aha and the forthlets designed for VentureForth. The counting happens in the editor where it should.
In the big comment benchmark all aha had to do was read the comment tag from the DRAM source, execute a few instructions in fast SRAM to know it is a counted comment. Then it just reads the count, adds it the pointer and it past the big comment field in 202ns regardless of how many characters there are up to the limit of the memory size of the computer. I had only packed two ASCII characters per word so advancing the pointer past one million words of comments was two million characters in 202ns or 0.000101ns per ASCII character. People who didn't with CAD were not used to using picoseconds or femtoseconds. I said, "Yes that's 101 femtoseconds per ASCII character.
Aha does lots of stuff like that. It doesn't work like Forth that follow the forty year old compile loop described in Elizabeth Rather's book. Being able to compile Forth words to executable object code at a maximum rate of about 250 million source words per second on a $1 chip is also a little hard for people who haven't studied it or understand that at times compiling four source words into four executable words in memory takes one memory store.
You might find the rational for the tests and the results of the Modern Forth Compiler Benchmark tests interesting. The web page is Modern Forth Compiler Bencharks.
this is a test this is a test I saw a link to a very nice toy recently. Its related to my life outside of Forth and programming.
There are two web pages about it in French with some wonderful pictures of it and some bigger more expensive toys. If you don't speak French you can get the pages translated using the web.


I had some trouble distinguishing it from the full sized version in some of the photographs. You really have to look closely.
You can see more great photos and read about it at Les Grands Planeurs Rc and Stemme S10-VT de Grard BON...
Some related pages include Martin Hellman's Links to Soaring Photos, a very nice YouTube video of Garret Willat from Sky Sailing in Soutern California, and a great story about an adventure of the late Thierry Thys Spine of the Americas soaring adventure of a lifetime
Oh! I have slipped the surly bonds of Earth
And danced the skies on laughter-silvered wings;
Early this month I was directed to check out a blog entry about Yossi Kreinin's experiences with Forth. I found it interesting.
My-history-with-forth-stack-machines on the blog "Proper Fixation (a substitute for anaesthesia)"
I found it quoted me in several sections. The first two quotes I was happy with. Yes I have said that there is a difference between pros and Joes. There is difference. Joes usually want to play and results don't matter much. Joes may be happy to show others just how bad their code is.
Joes may want to learn or just have fun and are likely to do that no matter what they do. Often they want to write their own Forth but have no real reason to do so, no plans for what to do with it, nor any use for it in the future. Pros usually have a goal of doing something that has never been done before and they try to do the best job they can. Their job itself is likely to depend on how good of a job they do.
I tend to have a lot of opinions, more than I am comfortable with at times so I like to try to consider other pointes of view. But one of the things I have trouble understanding is when people say that they want to do Forth and then sit down to write code in "C" or something other than Forth instead. When then finish writing code in "C" they may feel that they have been doing Forth and show other "C" programmers how Forth is about writing code in "C".
What is Forth? Among other things it is compiler. I ran some benchmarks recently on a number of popular modern Forth compilers on my PC. The Forth mentioned in the article was one of them, pForth. I think the "p" is for "portable" like another older Forth in "C", PFE the Portable Forth Environment. (maybe instead the letter P in pForth stands for Paul.)
Forth has always been the most portable and easy to port language going back to the days when it was almost always the first language implemented on every new computer design. But here the term is being used in the sense that many "C" programmers think that "C" defines portability when they focus on the narrow range of machines where "C" is used. By numbers most computers are too small for "C" to make sense. On some machines "C" does offer some degree of portability.
But I wince a bit when I see people promoting a Forth written in "C" when the performance of the system is only about one percent of the performance of Forth written in Forth. Chuck Moore has said many times that good Forth code should be about one hundred times smaller than "C" code. That upsets many "C" programmers. I found it interesting that in every benchmark I had recently done that pForth was almost exactly one hundred times slower than the Forth I use.
We already know that many "C" programmers really don't like Forth at all and many Forth programmers don't like "C" at all. As Chuck always said when you show people Forth a quarter will love it, a quarter will hate it, and half will be indifferent. The ones who hate Forth often have experience with things like "C". Forth and "C" are sort of natural enemies because compete for jobs on the larger embedded systems.
I have even heard people say that they like Forth because it is good as a simple debugger to help them debug their buggy "C" code. While true it is usually a statement that the person only likes 1% of Forth but doesn't know, denies, or doesn't think much of the rest of it. If that is the only good thing they can say about it then I think they hate Forth. It makes me think of a quotation.
" There's nothing I like less than bad arguments for a view that I hold dear." Daniel Dennett
When someone evaluates Forth by looking at something written in "C" because the author knew "C" instead of Forth I wince. When they then show it to others I wince again. I think they are not giving Forth a fair chance at all.
If you show them an awful "C" compiler written in Forth they will tell you it is because Forth is awful. If you show them an awful Forth written in "C" they will tell you it is because Forth is awful. And many people take the 1% performance Forth stuff seriously.
Here we have someone who jumps into Forth, right into the "C", gives it a brief look and writes that he "sort of understood it." Then he showed "C" code. He sort of got it too. That sort of thing usully takes about fifteen minutes.
He then quotes my comments about how professional Forth programmers and hobbiest who write Forth systems for fun don't have much in common. He seemed to get my point too that dead frogs stink.
But he says, "Ouch. Quite an assault not just on a fraction of a particular community, but on language geeks in general."
I hardly considered asking people to consider the nature of what they want to do in the name of Forth an assault. I have written things that were an assault on language geeks in general but that was hardly it. I say that it is not just language geeks but modern society as a whole where the emphasis on language has seriously diminished people's other mental and physical abilities. There are a lot of things that are very much like texting while driving. I just hope it doesn't kill you, your friends, or your family.
I don't mind people using 1% performance Forth, of using 1% Forth, or using Forth only 1% of the time. I only object when they tell others that it is the best Forth can do.
I have written a lot on my history of working with Chuck Moore on the design and programming of a half dozen generations of Forth hardware and a hundred different approaches to Forth software. Look at Chuck's history. He invented Forth and then learned what worked and what didn't by using it exclusively for programming for twenty years. After mastering Forth he declared that, "The software problem is solved." He felt that the problem that remained was that hardware was still inefficient and could be difficult to program. So he set out to take Forth beyond just software into hardware design. He wanted hardware to be Forth software also.
Only after twenty years of full time practice and of mastering Forth software was he prepared to attack the problem of designing hardware in software. In his first two efforts he didn't do it in Forth softwre but used the same conventional tools other programmers used. He was not happy with the ugly, inefficient, difficult to use, black box CAD software that had to be used. He wanted control and to understand everything he was doing. He wanted source to all the tools.
It didn't happen overnight. It was quite a problem to solve. The early days when the National Security Agency released the CMOS component library description to the public. when Chuck was learning from it, and when Dr. Ting wrote the Forth VLSI Hacker's Toolkit were very intersting times indeed.
Most hardware experts denied any knowledge of what their CAD software was actually doing beneith the hood. They had the same attitude as many programmers have, their tools are smarter than they are and they just have to blindly trust in them because there is no hope of them every understanding what they are actually doing.
When Chuck found CAD experts and people who had written CAD code they would almost always say that they could answer questions about 1% of anything because that was the most they knew. The other 99% was a black box that they had to blindly trust. Forth programmers prefer understanding to black boxes and have learned not to rely on blind trust.
After each few years and each generation of new Forth chip designs Forth software evolved too. To quote Marshal McLuhan, "It is a loop. We make out tools and then our tools make us."
But seriously, how can someone design a good Forth CPU without first having written lots of applications in Forth, and profiled their intended applications to know what this processor is going to need to do? Since a person can sort of get Forth in fifteen minutes they can jump into this loop wherever they want but will they have unrealist expectations?
Learning most things requires work step by step, stage by stage under the guidance of good teacher or better yet a master of the art. When people don't do that they tend to just perfect their bad habits. If they don't do their homework in the first place to get a strong foundation then they are likely to be building on soft sand.
The author of the blog wrote, "I defined the instruction set in a couple of hours."
I had ten years of experience programming in Forth and then I spent five more years working with Chuck testing software against possible design variations before we arrived at the F21 instruction set. Maybe I am just slow or Yossi is just that much smarter than I to get his results so fast. This chip's instruction set was designed in a couple of hours by someone with no previous background in Forth programming? He even admitted that he didn't even bother with homework like reading the excellent but twenty three year old book textbook on the subject by Dr. Koopman, "Stack Computers: the new Wave."
The author says he assumes that knowledgable people would have sneered at his machine. I wouldn't have had it been done as a learning project by a ten year old who had done his homework. But this was suppose to be professional quality Forth work. He was being paid. People were counting on him to do a good job and he jumped in with no experience, doing no homework, and designed the instruction set in a couple of hours?
Next the author showed his ability at writing in Forth by leaving Forth behind from the start. He wrote, "The first thing I did was write a Forth cross-compiler for the machine - a 700-line C++ file (and for reasons unknown, the slowest-compiling C++ code that I had ever seen)."
He didn't just leave Forth behind. He says he intentionally left out all the examples that drove him to drove him to Forth in the first place. He said he had no WORD, no COMPILE, no IMMEDIATE, no CREATE/DOES>, no nothing. He did just colon definitions, RPN syntax, and flow control words. One might think he was telling a joke not describing professional software development.
Then I looked at some of the Forth code he had written. Again I winced as it looked like someone who sort of got a percent or two of Forth.
Programmers without experience in Forth often have trouble with the whole notion of stack code at first. They are told that after a while it becomes like riding a bicycle, it is reflex and you keep your balance unconsciously while thinking about the problem being solved. They are told that it is quite natural and easy to do. This code looked more to me like a drunken sailor's first attempt to ride a unicycle blindfolded.
He quotes Chuck as saying that stacks are not popular where Chuck added that he didn't understand why they were not more popular.
Years ago I offered Chuck an explanation for that. I said, "Stacks are about the worst thing in "C" code. Their stacks are complex structures in memory. They are slower than memory itself. They are the source of all sorts of errors. They overflow. They underflow. They throw errors. They are a weak spot that malicious software and and viruses attack. They are completely different than stacks in Forth. When other programmers hear the term stack they think of the worst thing in the language they know."
I added, "It is easy to understand why what they call stacks in other languages are not popular and why Forth sounds so bad to them. To you stacks have come to mean something simple, fast, elegant and easy to program. You think of a stack as not being able to overflow, not being able to underflow, not being able to throw any errors. You think of stack as being many times faster than memory let alone stacks in memory! You think of stacks as faster than general purpose registers. You think of stacks as a mechanism to compress programs."
Look at F21 as an example. It has 2ns stack access and compare that to its 40ns to 140ns access to DRAM or its 18ns access to SRAM. We think of stacks as being smaller, cheaper, and faster than general purpose registers because that's what they are in our designs.
Consider how different stacks are in Forth and "C" by noting that the MuP21 had a total of ten cells in its two stacks. Chuck wrote that it was about the minimal size to allow one to write good Forth code. Compare that to the bug report I found in Bugzilla for GCC bugs. "C" programmers complained that there was bug in their compiler when you specified stack frames larger than 4 gigabytes!
It is hard to imagine a bigger difference in meaning for the same term, stack, than in the minds of those two types of programmers.
Then as if he wanted to prove Chuck's point the author said just the opposite thing as Chuck. He wondered why stacks were so popular at all.
Based on these exactly backwards ideas about Forth the author said that he began to miss a "C" compiler. Is there any wonder why?
He asked, "What does this say about Forth? Not much except that it isn't for me."
My answer to that question would be that it shows that no one likes Forth done in the worst possible way except programmers out to prove how bad it can be.
But in a sense he did seem to get a little of the problem he had. He wrote that a good Forth programmer would probably do everything differently. Indeed.
He quotes me again describing how Forth uses factoring of a problem to simplify it. In the example Chuck explained how other people use SPICE equations to solve three simultaneous differential equations in floating point to get a result to five decimal places that is actually only accurate to about 50% while Chuck carefully scaled his integer computation to get results that are actually accurate to several decimal places and by just doing a couple shifts and adds. But the author didn't get the lesson of fractional integer math at all.
When Chuck showed this line of code to someone he was asked how long it took him to write that line of code. He replied, "About fifteen years." He meant of course that only by making it better and better over and over again for fifteen years did it get to the point that it was as good as it was.
The blog author seemed to understand that he was really not doing quite the same thing as Chuck at all. He wrote, "This is Forth. Seriously. Forth is not the language. He wasn't as blind as many language geeks in that regard. He knew more than those who insist Forth is nothing more than a language syntax.
Then I found something where he quoted me again but didn't get my idea at all. I think he completely misrepresented what I had said. I had heard it before from Forth haters.
He said that according to Jeff Fox doing everything in-house was essentially a precondition to "doing Forth" at all.
What I have actually said is that if you are doing some percent of your work in something other than Forth then you are not spending that time doing Forth. Choosing to use Forth is a precondition to doing Forth.
We have heard all these same arguments before. "C" stacks are terrible so because Forth uses stacks it must be terrible. They can prove Forth is bad by showing us their Forth code. They would only consider Forth when it is in fact a "C" program that runs at 1% of the speed of Forth in Forth. They can write "C" programs in Forth but they are not as good as their "C" programs in "C". When they try (what they call) Forth they miss their "C" compiler.
I don't know why they say they miss their "C" compiler at all when they cling to it like a teddy-bear while claiming to be evaluting Forth. We have heard all that before. I have heard it many times. And I realize that these are the things that "C" programmers tell each other about Forth so they can sleep at night.
I tell the story about when Chuck gave his first public presentation on my chip, the F21. I was so happy that Chuck only talked about what he had done. Not once did he mention Intel, other CAD software or "C", not once! So when he finished I asked I guy I had never seen before what he thought of the presentation and he told me.
He said, "I hated it! He called me an idiot for using "C" all my life."
It is amazing how people people react when hear a factual account of what someone did with Forth. They questions assumptions they made in the past and often get very upset.
In comments and dialogs with other people at the end of the essay Yossi Kreinin said, "This is one of the pitfalls of integers - that they don't represent numbers less than one."
That's a perfect example of someone who has not yet grasped the basics of Forth programming or done any homework on its history. Scaled fractional integer math has always been one of Forth's strong points. He had even previously quoted an example of it and not realized it.
Chuck would often find himself at the opposite end of the computing philosphy spectrum from one well known "C" expert when Chuck started attending Silicon Valley Forth Interest Group Meetings. Chuck would be giving a presentation about his design work on small chips for Forth and say something like, "The best way to do this addition is with a very small adder that uses ripple carry. It is slower for large numbers than a bigger and more complex adder that would make the chip bigger and more expensive and power hungry. For small numbers the smaller adder is faster and thus you have the freedom to do add small numbers faster when you want to and all you have to do is add a nop before the add when you want to add large numbers. It is the best solution for this problem because it only adds a few dozen transistors to the design, lets the code run faster, and offers you more freedom."
Then Chuck would be interrupted by someone shouting, "The best way to do an add is to let the hardware convert the integers into floating point, do a floating point addition, then convert the numbers back to interger for you!"
The "best solution" to put an adder on a chip designed to cost a few cents and draw a few milliwatts is to add a few hundred million transistors so it will work like a Pentium? Someone needs to interrupt Chuck's presentations on the way small Forth chips are designed to tell him that?
It seems that a lot of programmers just don't get what Forth is all about or what small Forth chips are about. Desktop programmers today are so much the mainframe programmers when microprocessors were invented They don't undertand what the terms used in Forth mean because they assume that everything must be like "C" and on hardware designed to run their "C" code.
I found Yossi's blog to be an excellent example of many of the points I have made many times. I found it quite interesting read. Still I am sure my take on it is quite different than what most people will think of it.
11/22/09 Silicon Valley Forth Interest Group Forth Day 2009 Plus One
The Silicon Valley Forth Interest Group's Forth Day took
place yesterday at Stanford and was enjoyed by about the
same number of people as last year. It closely followed
the agenda currently listed at the forth.org website
which is pretty self-explanatory.
SVFIG
Forth Day 2009 Photos (at Forth.org)
There was old stuff, new stuff, evolutionary stuff, and
some innovative reports. Video were made and photos taken
that will be posted by SVFIG just like last year. There
was lots of interesting stuff. I won't comment on it all
but am willing to answer a few questions if I can. Dr.
Ting had an interesting approach to eForth in C.
The report on details of the Forth Foundation Library
should be of interest to a lot of c.l.f readers with
opinions about library projects as it seems to be
pretty mature at this point.
Leon did a step-by-step demonstration of how to
start a project, compile a system on a chip onto an
FPGA with a soft processor core, target compile an
application using Swift-X and get it all running
very quickly while answering questions and making
it all look easy.
IntellaSys and Green Arrays had quite a few people
attending and a few presenting. I already knew quite
a bit about the hearing enhancement project but it
was very nice to get a report and hear an actual
hearing aid device working. I very much enjoyed
Michael's presentation. The algorithms used in this
hearding aid
are quite sophisticated and the previous prototype
which used TI DSP chips was nearly the size of a
laptop. I was impressed by how much the size
of the application had been reduced in the Forth
version for S40.
Since only a small fraction of processing power of
the S40 is used in the application so much of the
device doesn't consume power most of the time and
battery life can be maximized. I would live to have
one of the devices to play with to host s40 based
interacive voice based apps in an ear bud.
I talked about the Interactive Development Environment
for target chips in colorforth and reviewed a version
of the
PWM Serial boot packet and/or neighbor
boot routine from a GA4 ROM that I had presented
earlier in the year to a small audience. I answered
the question I had posed for the reader about the
little optimization one could do on the routine I
had shown. I talked a little about blue words and
the design of the target compiler and IDE in
colorforth. I talked about the blog entry I had
made about optimizing your structures in Forth and
got a few nods from Chuck for comments about the
example code. I said I wanted to show more than
what was normally show to beginners when the subject
comes up.
My finger is pointing to the GA4 chip which is both
talking to the colorforth IDE on an asynchronous
serial connection and being booted by the GA32 in
the socketed blue board on the right which is also talking
to the colorforth IDE over a USB/synchronous serial
connection. There is also a small 1.8V to rs232
converter board above the GA4 board. The GA32 is
sending a PWM Serial boot packet using XMIT routine
at 31MBPS to run test code on the GA4.
I pointed out that when one sets up a path to a
target node in the colorforth IDE to interactively
talk to it as if it were running a Forth interpreter
with a command line that it had to be the smallest
such Forth system as it uses the minimal amount of
RAM and ROM. The minimum RAM/ROM footprint being
zero.
Chuck showed colorforth code for the Haypress Creek
board and using the IDE showed several small
applications using a small amount of the resources
on the board to generate video and display several
clocks in one of three fonts. Greg announced that
they would soon be releasing several versions of
colorforth with the compressed code, blue and grey
words, multiple fonts, watermarks, documentation,
and with a target compiler and software simulator
for each of the GA4, GA32, and GA144 chips. All
other OKAD application programs and the chip designs
themselves will of course be stripped from these
public colorforth releases.
I had wanted to do an interpretive reading of
John Gillespie Magee's poem
High Flight
but there really wasn't time. Chuck commented in his time that he
had selected some poems at his website that were meaninful to him.

11/19/09 Silicon Valley Forth Interest Group Forth Day 2009 Minus Two
The annual Forth Day in Silicon Valley is comming up this Saturday
and I have offered to give a short talk (well short for me, I can
still talk your ears off if given the chance). Since I haven't been going
down to Silicon Valley on weekdays like I had been doing for a few years
to work with interesting people at IntellaSys I look forward to seeing
some of them at the Silicon Valley Forth Day get together. Chuck had a
party up at his home in the Sierra last month and it was a fun visit.
I said I would review some of the blog entries I made this year, and
follow up a bit on the presentation I did at SVFIG earlier this year.
I will show the Interactive Development Environment for target Green
Arrays chips in colorforth. I am using the same IntellaSys board for
the GA32 testing as I use with the SEA40. The board has a socket and
all the 32 and 40 core designs have been put into the same package so
they all work on the development board with the ZIF socket. All it
needs is a USB cable to the PC and ventureForth or colorforth will
recognize the board and allow target Forth development with incremental
compilation.
I also have a board with a GA4 that uses an asynchronous interface and
is connected to a rs232 converter board. That one can be used with
the tower I have that runs colorforth native and has a serial port or
I can use it on a windows PC using a USB to serial card. Using
colorforth windows hosted I can run two instances of colorforth in
different windows. One can be setup to talk to the IDE on the USB
bus to the GA32. I could show this setup and show how I used the
PWM serial output on the GA32 to boot code on a GA4 while running
the IDE to the GA4 in a different window. I can run the tests
with either a direct connect between the GA32 and GA4 boards or
with a capacitive connect. The only problem is that the GA4 board
I have needs a small bench power supply and so isn't as portable as
the GA32 board and hauling in a couple of boards and a bench power
supply is one more thing to setup for a a demo. I probably will just
show a GA32 talking to colorforth.
As is often the case this is a year when there are some things
we can freely talk about and some things that we can't. Some
of the most interesting stuff as always is quite technical but
isn't public so it isn't for Forth Day. But what we do with or
have learned about the software is fair game as always.
I talked about this IDE to SVFIG earlier this year and made a blog
entry about it
10/17/09 Green Arrays GA4 Boot Software Simplified Again.
But this time I will show the IDE talking to the hardware. I know
that there is some debate about what constitutes a minimal Forth
system, or a Forth system at all. The ability of the c18 design
to execute an instruction stream of Forth opcodes on a real
(not virtual) Forth machine removes much of the complexity of
traditional Forth systems and reduces the amount of ROM and RAM
needed to execute Forth programs. And the minimum is zero.
A target c18 processor may have booted to ROM code or it may have
booted to the address of multiple shared registers with other c18.
In the later case zero words of RAM or ROM or needed on that processor
as a neighbor or group of processors can feed it a sequence of Forth
code to execute. Originally these chips all booted to ROM and executed
some code sequence to be able execute incoming Forth code but over
the years the design evolved so that most c18 boot to an RDLU multiport
address and go to sleep waiting for Forth code without ever executing
any ROM or RAM. These computers take about a nanosecond from powerup to get
to a state ready to run incoming Forth programs with a delay of a couple of hundred
picoseconds, they run Forth up to 700 million Forth opcodes per second,
they draw only a few mw per billions of Forth opcodes per second, have
high speed high analog hardware on board, scale in arrays, use
about $.01 worth of silicon each, and only need simple Forth tools.
The colorforth target IDE uses this to setup paths from the place
on a chip where it connects to a target chip to other c18 on that chip.
One can change paths and talk to different c18 in the grid at different
times. The IDE lets one look at the stack and registers, put literals
on the stack, fetch and store memory or registers, dump memory, or load and execute programs
on any c18. It provides an interactive Forth user interface running
in colorforth on the PC and possibly in multiple c18 nodes acting
as temporary message pumps connecting the user at the colorforth console
to the interactive Forth user interface on any c18 in the network.
I will try to keep the demo simple with just one target chip, GA32,
and show how easy it is to turn an lcd on or off on the target board
with an interactive command or load and run a test program written in
coloforth. I will also talk a little about the design of the code itself. This is after all a
group of people interested in Forth and sometimes Forth coding that
will the audience. The point I will want to make is that it is MUCH
simpler than your typical target Forth not just because the target has
no primitive defintions or virtual machine definitions but also because
of the way the target compiler and IDE work in colorforth. Some things
are done in a way that is very different than that used in almost all
ANS Forth target compiling or meta compiling systems, and much simpler.
The wordlist problem issues are simply avoided. The word DUP exists as
a colorforth macro specifying a colorforth 32-bit stack operation and as a
target c18 Forth word specifying a target 5-bit opcode for the 18-bit wide stack in the target
compiler or as an interactive command in the target IDE. Color specifies type of use.
There is a conflict that is not resolved. The problem that other people
address with wordlists is simply avoided. The code is either colorforth
code or target code or IDE code at any one time. There is no need to be
able to jump between the three environments when using the IDE. Wordlists
are not used to mix code in the three environments, things are simply
defined in the order needed. When things are simply compiled from source
in a programmer specified order many problems are avoided.
I'll try to give some of my time to the guys who have made internal changes
to colorforth this year. Or perhaps I will just ask them to list the
various internal changes. But I would like to see they guys talk about the
changes to color tokens, to the editor, the new fonts, the new Green Arrays
Softsim application that might get released to the public, the IDE and
documentation, and possible plans to make a new colorforth release to the
public. Forth day might be a good place to discuss ideas about future
changes to colorforth. I may explore that a bit too and see what people
think before I do my presentation.
I made a trip to Austria in 2007 to work with the team developing the hearing
enchancement project for IntellaSys. It is a fascination project. I followed
up with a visit with my old friend Soeren Tiedemann in Berlin. He showed me
a really great time. One thing I found remarkable was that every morning
that I was in Austria or Germany there was at least one morning show from a
gliderport somewhere. Rarely does TV show people flying in sailplanes
here in the US.
The hearing enhancement project moved to the US for porting to IntellaSys technology and
was the only project that continued after most everyone working for IntellaSys
got laid off back in January of this year. Dr. Montvelishsky stayed on to work
on the hearing enhancement project and will be giving an update at Forth Day
that I look forward to with great anticipation.
As the original author of ventureForth I look forward to seeing what Dennis
Ruffer has done with front end. The idea was that we were trying to enable
other people to do that sort of thing and it will be interesting to see him
demonstrate what he has done with it. I expect to be educated by John Rible's
presentation on his new double square root code. And as always I look forward to
seeing Chuck give his presentation as he is always entertaining. If I left
your presentation out don't be offended I am sure I will enjoy it and will
write something about it.
It is wonderful to see the technical success with cad, circuit design, chip
design, packaging, layout, and system programming. I hope at some point that
there will be a project generating financial success so that the details of
the technical success can be shared with more people. If you like Forth because
it is simple and easy or exceedingly productive then this is good Forth stuff.
If you prefer stuff only on the most well troden paths then this probably isn't
for you.
10/23/09 Forth Style Structures
One newbie question that often comes up in comp.lang.forth is about
the use of structures in Forth. Forth isn't C, it is different.
The C programming language has an essential feature called structures.
Structures or more specifically syntax for data structures is specified
in C. Structures allow one to give names to programmer defined data
structures that may occur in more than one place a program. In C
they can be thought of as records with named and typed fields and
are used in C to provide an abstracted view of these data records
and their fields. The C compiler is responsible for generating
the actual structure and the code that accesses the structure and
optionally for optimizing the generated object code. C is regarded by
many as a sort of portable assembler but with some very useful
abstractions like structure specification, abstracted
data structure access and external I/O libraries. Optionally
optimization is applied globally by the compiler as needed
with the intention that optional structure access code can be generated
and will be as small or fast as possible for a given processor.
In my page about essential Forth I talk about how many early Forth
programs were databases that greatly outperformed the competition
partially because they were not built on top of the file systems
of common OS. When newbies ask about databases or about
structures in Forth they are given varying advice and usually
some tutorials reviewing how the abstraction of data records
was done in these early Forth systems some thirty some years ago.
Forth has many differences from C. There is no standard syntax for
structures in Forth even though it is an essential feature in C.
There are many other similar examples, there is also no standard
syntax for arrays in Forth even though that is an essential feature
in many languages. Because Forth programmers have many different
variations of structures or arrays and because they have the
freedom to define much of the syntax they use they approach
structures or arrays in a way that is different than in C.
This sort of thing often leads to a lot of confusion. It is
simply a matter of Forth having its own way of doing things. But
when people are familar with another environment
they will usually first frame their questions about Forth by
asking how one does the things they do in their favorite language
and often we don't do the things they do, we do something
substantially different. And again this is a generic experience.
A common example is, "How do you do C style ...in Forth?"
Often it is like asking a basketball player what soccer techniques
they use to kick their ball. It is like asking a mechanic which wrench
they use to drive nails. The only answer is, "We don't."
When C programmers ask how Forth programmers do C style this or that
the answer they often get from people who are just using Forth and not
using or selling a mix of Forth and
C style is simply, "We don't." This tends to upset them.
But the, "We don't." answer really is simple, direct, and honest. But
let me detail some of what we do instead and give and example.
In comp.lang.forth recently we were told that when C programmers
hear the "We don't." answer they natually assume that "We don't" means "We can't."
We were told that "anti-Forth C enthusiasts" then feel "armed" to
go out and tell other people that Forth simply "can't" do the
things that are essential to programming.
We have all seen it a hundred times and it was explained
to us again recently in c.l.f that anti-Forth C enthusiasts get
upset when told that we don't do everything the way that they
do it in C. It is just absurd that people in c.l.f tell others that
Chuck Moore obviously "can't" do things that they can teach to Forth newbies.
Structures in Forth? We do use them but we don't
do them like in C. And there is no dogma about their use. It is
a lot like how we use arrays. It is not specified in the language
so that we have more options. We use arrays but we don't do them
all one way with a rigid syntax like in C. The same is true for
structures. We customize our arrays and structures and focus
our optimization. Forth practice is more about pragmatic choices
of what works best in a given situation.
Applications use the appropriate structures for high level
code, but only where appropriate. One thing that makes Forth
different is that we can drop below the level of the structure
where that is appropriate, and knowing when that is appropriate
is part of the art.
In c.l.f when newbies ask they get answers for newbies. They get shown
an example of simple structure use based on defining words that
allow data structures to be defined with named and typed fields.
Newbies get shown simple examples of how things were taught to
beginners in Forth forty years ago. It is the stuff I was shown
before I started to work with Chuck Moore. I saw that he
would work hard to eliminate as much of the base plus offset
calculations so common people's C style structure implementations
in Forth. On one hand you have people adding a 100x overhead to
their C style high level Forth base plus offset calculated
abstract structure code in the name of making it more portable.
It is sort of doing the opposite of what Chuck calls Forth.
An example was the old Forth Scientific Library structure code.
Take the simple newbie examples of simple structures in Forth
like were done forty years ago that are shown in c.lf and
make the code many times bigger and slower by adding runtime code
to make it more portable in a C library sense. Real C is likely to do
speed optimization but C style Forth sort of gets the worst of both
worlds. In contrast to that Chuck Moore started
with the idea of the simple forty year old Forth structure and then
working out how to eliminate 90% of the base plus offset calculation
and pointer manipulation in the dynamic execution of the
Forth style structure code.
What is usually promoted in c.l.f. is just the opposite of
the kind of Forth done by Chuck Moore where he starts with
the simple forty year old code and then makes it much more
efficient by eliminating waste. There is a difference
between N*100 and N/100 (except when N is zero). With things going in the opposite
directions at iTV we had experiences of converting 100x code to 100/ code. It is
hard to understand why some people are so against such gains.
Converting 'standard' C-style Forth code
to optimal code will usually give very dramatic results.
The simple stuff from forty years ago
seems like good stuff for newbie green belt exercises
but unfortunately it seems it is as far as most people ever get.
Most people it seems don't
get exposed to more advanced or more modern Forth practice
regarding the efficient use of structures in Forth. It seems ok to me that this is
what beginners are shown when they ask. I just hope they continue
on to learn more and not get stuck at the beginner level or taking
the "easy" way out of the process. I happen to think it is easy
to count the number of offset calculations that can be eliminated
from many implementations to measure some of their inefficiency.
One way that Forth differs from C is that the level of abstraction
in Forth is more variable than in C as C has a fixed syntax forming
the lowest level. Forth has less of that and requires more
custom syntax for specific problems, for instance you define the
way you want arrays or structures to work.
Another way Forth is different than C is that the level of abstraction
used in Forth is more variable than in C as Forth can drop below the
level of the structure syntax. It can use the structured view in one
place and a lower level view in another place by just using different
methods.
If you don't want to do Forth like Forth you can always do Forth like C.
If you stick with use of the abstracted view only, if you don't take
responsibility for profiling and optimizing critical sections of code
and prefer to rely on global optimization by the compiler, if you don't customize
the use of your arrays and structures and always use the same fixed syntax or
first go to a popular high level library then you can keep doing things like
you did them in C. It is easy. If you don't like Forth stacks you can use
locals like in C. If you don't like Forth blocks and Forth OS you can use a
foreign C file system and OS. If you don't like the Forth dictionary you
can use a C file system instead. It is easy to do and lots of people will
help you do it. These are style issues but part of the picture.
Let me offer some code as a further example of how we use structures.
I think that the
use of Forth structures in the GUI in 4OS can provide some quantative
analysis and allow a comparison of C style structures in Forth with
Forth sytle structures. In 4OS the GUI structures code was dramatically different
than the FSL C Style Structure code that had been pasted in to support
network and socket code copied from C to Forth.
IMHO a principle in Forth is to implement only what you need and remove
what you don't really need. So we can look at what was done in C structures style
programming in Forth and its results and compare them Forth style structures
in Forth from a real example from the real world a little over a decade ago.
While I love the details of how a simple GUI can work in Forth
I will simplify the example here to focus just on the structure part of
the picture. The example is taken from the GUI I put into 4OS. In
that system there was a user variable named WIN. WIN pointed to the
window structure being used. Each task had its own WIN pointer and
each task could point to any window structure to do I/O.
The C approach is fixed syntax and global optimization. In Forth it
is the programmer's responsibility to oversee optimization. Code
profiling of the application showed that 98% of GUI calls were to one
routine with about a 0.2% frequency for most of the other GUI functions.
One function deserved more attention than most in typical Forth style
and Forth offers the ability to drop below the high level structure
we may use elsewhere.
After first being defined in a forty year old old fashion style
the details of the structure were modified to be most efficient on the
most frequently called code. The contents of the data fields in the
4OS window structure and their order evolved as it was developed.
The window structure was defined in a conventional way like that
shown to newbies when they ask. The abstracted view of the structure
was used in 90% of the routines but these routines are only called 2%
of the time. The abstracted view was not used in 10% of the code which
was called 99% of the time because it was easier and clearer to specify
the way in which that code was to be optimized for minimal size and maximum
speed that way. The most important code is written below the level of the
structure syntax itself. Like many other things the strategies used in
C and Forth are very different.
In this example the details of what the GUI did will be removed
so we can focus on just the structure access and compare the source and
object code that results from the two different approaches. So
the real field names like X, Y, width, height, font-height, etc. have
been replaced by names X1, X2, X3, X4, X5 etc. and the real GUI code
will be replaced by code that sums up the fields and does one
store back to a field. High level abstracted code is provided
for access to the named fields in other high level abstracted code.
In this case the effect is that a reference to X1 compiles code that
takes the address of the current structure in use, pointed to
by the WIN user variable (which involves adding an offset),
loads the offset appropriate for the
Xx field, adds the base address and offset to get the address
of that field in the referenced structure. In this case a copy of the
"window" structure is what the WIN user variable points to and so
the definition of the field names is an offset to the contents of
the WIN user variable.
The real GUI routines, even just bit-blitting a character to the
screen involved more processing of the contents of the fields of
the window data structure than in this example. I want to just
focus on the structure access so present a minimal amount of
processing on the structure in the example.
The character display routine from 4OS used the style presented
here as the word FUN1. The word FUN1 fetches from structure fields X1,
X2, X3, X4, and X5, adding the values and storing the
result back to the X5 field of the window structure being used.
That's our abstracted view in this example. And in C style structures
we would rely on the optimizing compiler to generate optimal code to do this.
How good is your Forth compiler at that?
Since WIN is a user variable it takes a pointer to the user area
and address the user variable offset to get the address of WIN.
One fetches from the address from WIN to get the base address of
the window structure. The offset for the field is added to the base
and all of that is done each time an X1 to X5 is invoked. Here is
a example of compiled inlined threaded code for a Forth virtual
machine used in the ANS Forth 4OS and which would be pretty typical
for most threaded Forth.
That has twelve offset calculations. Maybe your optimizing compiler
is more agressive than the one in this example which has simply inlined
the code for structure fields to remove any overhead norally imposed
by implemenations that also imposed a ":" and ";" overhead
on each field invocation. Maybe your compiler can optimize the
user variable offset addition as an addressing mode or
eliminate the first field offset calculation of "0 CELLS +". Or
perhaps your compiler can perform global register optimization over
the scope of this code.
Compile your own structure code to total five integer fields
in your own user variable accessible structure and have it write the
result back to the last field. Compile it with your own Forth
compiler and see how many of the offset calculations it can
remove, how much register caching it does, or whatever else it
can do.
In the Forth style approach to structures we know that this needs
to be optimized so we do that. We can specify the way we want our
code to access the required fields.
In Forth we are not required to use the rigid syntax of C and stay
within any one abstracted view or to rely on the optimzing compiler to
do the object code optimization. Nor are we required to stick
to the way it was done in Forth more than thirty years ago. And
that isn't what beginners are show. They are shown that
it is 'easy' to do it in C style.
Chuck's approach to Forth included some important changes to the
original forty year old virtual machine that he made more than
twenty years ago. He acknowledged that hardware had evolved since
the seventies and saw an opportunity for Forth to get closer to
the hardware. He split the traditional "@" and "!"
atoms used thirty and forty years ago. He made the observation
more than twenty years ago that from most 1980's hardware
on designs had auto-increment addressing mode instructions
and that these were difficult to map to Forth when Forth had to
use the stack for the fetch or store addressing. It often results in
a terrible bootleneck needing lots of SWAP and OVER
instructions in the Forth code to keep a pointer on the stack so that it can be manually
manipulated or as in the case of this type of code calculated each time. Getting an optimizing Forth compiler to generate
the minimal number of auto-incrementing memory access instructions
from code that specifies manipulation of an address on the stack is a
complex problem and more C style than Forth style.
We can split the old virtual machine primitive fetch,
"@", Forth word to its components "A!" and "@A"
which gets the pointer off the stack and caches it in a
register. After all this is how almost all hardware has actually worked
for thirty years even it if wasn't the way Forth or
common hardware worked forty years ago.
In 4OS most things were available in the ANSI Forth layer
where stacks were in memory but the word CODE invoked the
machineForth layer. Structure access in the important GUI
functions was done at the machineForth lever, though still
Forth. I have written some agressive optimizing native
code machineForth ANSI compilers that might produce this
code from the ANSI source but just specifying it is much
simpler. We use an auto-increment instruction to
eliminate the pointer arithmetic and eliminate the need
to load a base address and add a field offset for each
data access. We eliminate half the code in most of the
original fetch, "@", instructions in addition to
the pointer manipulation code. The use of "@A+" adds no overhead
in size or speed compared to "@A" but eliminates
much of the code.
This is roughly a 10x reduction in code size and a 10x
improvement in code speed over the forty year old simple
structures in Forth. The other way to go would be to make
the structures look more like C style structure than the
old Forth structures and this was what was done at iTV on the network
protocol code with the intention of making it look more like C because
it was being directly copied from C code.
When you use Forth style to optimize your Forth structure
access your milage may vary. Your compiler may remove
some of the overhead present when
C style structures are used in Forth. Try it yourself
with your compiler. Take the above example and define
X1 to X5 as integer fields
in a structure accessed through a user variable and
compile the definition of FUN1 and see what existence
proof you can generate for your FUN1 code.
Will your Forth compiler add overhead or remove overhead
and insert auto-increment instructions instead? Perhaps
your compiler recognized all that reseting of some addressing
register with sequential addresses and replaced it with
auto-increment mode code or perhaps it folded the twelve
offset calculations into address modes in the hardware
that didn't add any bytes or machine cycles to the solution.
Did you get your code down to one offset calculation or
down to less than ten bytes of object code?
The names X1 to X5 miss the point that these were not
the original order the arguments appeared in when it
was first coded in abstract Forth structures. It was only
after several rewrites that the best sequence for the
most efficient access to the fields where that was important
was determined and only then were they reorded to be sequential to allow the
maximum use of the auto-increment instructions in the access code.
IMHO it is also C style to go to the most popular
standard library and paste in a function. At iTV we
started with this C style in some of the code as some
code was copied from the Forth Scientific Library
and pasted into our application. The
original FSL structure code was again pretty typical
of standard C library code in that it was very inefficient
because of a pursuit of "C style portability". It is inefficient
even when compared to the forty year old style examples. The
methods and styles of programming used to get to those
dramatically different sections of Forth code in one
project were as interesting as the code itself.
Chuck has a related page on his site about good Forth code
being about as big as 1% of typical C code:
www.colorforth.com/1percent.html
Recommended related UltraTechnology pages:
Essential Forth
: FUN1 X1 @ X2 @ + X3 @ + X4 @ + X5 @ + X5 ! ;
WIN @ 0 CELLS + @ WIN @ 1 CELLS + @ + WIN @ 2 CELLS + @ +
WIN @ 3 CELLS + @ + WIN @ 4 CELLS + @ + WIN @ 4 CELLS + ! EXIT
: FUN1 WIN @ A! @A+ @A+ + @A+ + @A+ + @A + !A ;
C-Style Structures in Forth?
10/20/09 Oh I have slipped the surly bonds of earth
I can relate to Chuck's inclusion of John Gillespie Magee's poem
High Flight at his site.
I enjoy driving a lightweight plastic composite vintage sports car
on the famous California race tracks. It is a very different experience than everyday commute driving.
I also enjoy flying a high performance open class plastic composite motorglider. There is an
analogy to the kind of work I have done in Forth to make it possible to do these things.
Last year I moved from being checked out to fly trainers with just stick,
rudder, spoilers/brakes, airspeed indicator, altimeter, and yaw string
to a checkout for this more complex cockpit. These days I am working on
my commercial license.

Gliding along looking down at my home in Berkeley and the fog behind the Golden Gate.

10/17/09 Green Arrays GA4 Boot Software Simplified Again
If you have read Chuck's descriptions of GA32 and
GA4 chips at
his website you might have noticed one small enhancement to
GA4.
Following is a description of some code I wrote for the
first GA4 ROM and tested in OKAD simulation and later on
real chips when they returned from fab.
In the previous chips based on the c18 core
one would read garbage when awakened by a pin from
a left or up neighbor port address.
This meant you could not execute these ports and read them with the program
counter or you would execute garbage. The asynchronous bit-bang boot code
would go to sleep doing a data read on a four-port RDLU address. When
it would awaken it would discard the garbage read in case it had been
awakened by a pin. It would then check to see if the pin had changed to
awaken it and then deal with either the bit-bang asynchronous autobaud
boot protocol on the pin or execute the rest of an executable message send
by one of the on-chip neighbors. There was a rule that boot streams began
with a token of four nops since the first word might be discarded as garbage.
There was also code that resulted in a rule that boot streams had
to deliver words in pairs with little delay between the first and second
word so the boot node could find the second word of the message waiting
and the sender asleep sending it.
On GA4 Chuck simply notes that reading a left port will use a pin transition
as handshake and will read a constant defined in hardware. The constant is the opcode @b ;
It has significant implications for software that may not be obvious.
The important part of that is that you can now execute the port.
The processor will read @b ; and will read the value on the
pins if the B register is set with the address of IOCS. So you
don't have to read the port only as data to use the wake-up circuit.
And this simplifies boot code among other things. On GA4 the processor
can go to sleep on a 3 port read. If it is awakened by an on-chip
neighbor write it will execute the incoming boot stream in its entirety.
If it is awakened by the pin changing it will read the pin and
return to the program (in ROM). Reading the port with the program
counter instead of the A register also means that the A register
will be free for use by other code.
Chuck mentions this in his documentation but doesn't explain it as
much as I have here. He also mentions that it uses a pulse width
modulated boot stream format. The format is simpler than the SPI format
or the auto-baud asynchronous byte encoded format, or the synchronous
serial boot format. The code to transmit packets is 18 words and
the code to boot, setup and boot pwm format or boot from an on-chip
neighbor message is 18 words. The format is simple and
the code is simple.
I wrote some pwm receive and boot code and some
pwm transmit code for GA4. I found it interesting that independently I wrote
almost exactly the same code that Chuck had written. I expect
that Chuck probably arrived at the answer much faster than
I since he had the idea for the hardware change behind it
and made that change.
I ran the code in okad simulation and ran some similar code
on an older chip to test the pwm code with direct and capacitive coupling
connections. I tried to write a small and fast boot packet loader
that initializes the essential hardware and pointers,
communicates with external and internal hardware, loads
programs of any size, optionally executes them, loads overlays
into memory or routes programs and data to other computers. The
object code for the two Forth source words are each nine cells long. One
can see that with a tiny bit of training by glancing at the source
because the compiler and language are so simple.
This boot code boots a computer from any of three other
computers connected on right, left, and down ports. It will go to sleep
and wake up to execute an instruction stream sent by another on-chip computer
to its right or down ports. It will also awaken from sleep
within a few hundred picoseconds on pin transition events
and processes a pulse width modulation encoded serial code packet in a boot protocol.
In the PWM packet protocol the RCV word will awaken on each rising edge of a pulse
width encoded bit
and differentiate between a 3.7ns zero pulse and an 11.5ns one pulse, repeat,
and return with a complete word on the parameter stack.
The word COLD initializes registers for a safe restart
from any state then receives an address for post packet execution
which it pushes to the return stack. Then it receives a load or
forward destination address and puts it into the A addressing register.
It receieves a count for the number of data items in the packet and uses it
in a FOR-NEXT loop. In the loop it stores received
words at a destination port address or a memory address and if using
a memory address it increments it. When it exits the loop it removes
the loop counter and returns to the execution address on the return stack.
The source code
is thirty-two words of Forth. It is much shorter
than this partial explanation of it.
When I first wrote it I wrote the equivalent of "[ SWAP ] NEXT"
in colorforth, (yellow)SWAP (green)NEXT. When I looked at Chuck's
example he had used "XNEXT" instead and it was clear to me
that he had used the name XNEXT to mean to swap resolve addresses
at compile time and then do a NEXT. So I simplified my code to
use the shorter phrase.
This example is simple boot code and
the sort of example people teach to children at robotics club meetings. It is
simple code. When you are used to this kind of Forth you can read it very
quickly and easily. I think it is a good example of factoring. Everyone
says that factoring is good and that they factor. But we have seen people
in comp.lang.forth who say that they factor their code also say that
Chuck's "brutally factored" code examples make them want to "run away
screaming." I think it is good to show examples of modern factoring
because some people will like it.
It didn't have much hardware, only a few transistors,
to assist in the boot so software had
to be a little more complex by manually bit-banging pins. The PWM protocol
is a little simpler than some other formats. It takes more code to do
pwm without the executable pin-port and it takes a
little more code for the bit-bang autobaud asynchronous format used on
most serial ports, the synchronous bit-bang format, and the
SPI bit-bang boot protocol format on other similar processors in an array.
Using serializer/deserializer hardware to boot takes much less boot code than
these bit-banging boot packet load/route protocols. It is also an order of
magnitude faster but requires special hardware and not as flexible
as firmware in ROM or software in RAM. To a programmer the more an off-chip
neighbor looks like an on-chip neighbor the easier things will be.
On previous chips it takes about twice as much code to boot this way from
one of three source simply because you can't execute the port with the pin
wake-up because you will read garbage from a pin wake-up.
Because you read garbage you can't safely execute the port. So you have
to read it as data, drop the garbage, swap pointers etc. and it doubles
the size of the required code. How much code would it take on your
favorite processor to do these things and how fast would it be?
There are other hardware changes that make the chip more robust and
reduce current leakage as well as other hardware changes that change
software.
BTW I turned off display of the blue words in the colorforth code
I showed above, maybe you could see that too. In your mind's eye did you see
the blue CR after the -if in rcv and after the . in cold?
Now that I point it out can you see it?
Chuck likes his newest idea of blue words in colorforth as they colorize a different
time phase, edit time. Design time, edit time, compile time, and runtime are important to
Forth programmers but many programmers are thinking only about runtime only.
I think Chuck's blue words are a challange to other programmers.
How complicated is it for you to define Forth macros and embed tags in your source code
that will optionally either be displayed or hidden by your editor and will execute your named
Forth macros from inside your editor when you edit your source? How simple to implement and
use is your version of that? I have seen how complex it can be for some people and how
trivial it can be for others.
There is at least one optimization possible for the code shown above
on that model processor. Can you see it? A hint is that it saves about 1.5ns per word over
the code listed above and lets it run a fraction of a percent faster. I will leave it as
an exercise for the student to see the change that could save a little time above.
Other programmers have claimed that their language and their favorite hardware
follow the same programming patterns and that they can write code that is at
least as simple and compact as ours. So I challange you to submit your example
with less source and less object code to
initialize the hardware, boot, load, or load and execute, or
forward programs using one of two parallel ports or optionally by bit-banging
a pulse width encoded packet format on one pin. Then show me how fast it runs,
how much power it draws, and the cost of the processor.
06/23/09 Forth Day 2008 Follow-up
The Silicon Valley Forth Interest Group put the video that they shot at their
2008 Forth Day online this week. I reviewed the presentation that I gave. I
used to make transcripts but I haven't done that. Here is a link to the word
document that was the outline for much of my presentation last year. It is
not clear in the video.
Near the end of my presentation I talked a little about a talking voltmeter
demo but never showed it. Here
is that picture that you can't see well in video of the diagram of the layout
of the talking voltmeter demo.
The code samples a hardware A/D on node 36 and sends samples to node 35.
Node 35 linearizes samples using interpolation and a table on node 25.
Node 34 converts a number to decimal digits.
Node 33 uses digits to index into a sound table with spi address and length.
Node 32 plays reads spi address and lenght and sends it to the splitter.
Node 33 fills one buffer then the other and repeats.
Nodes 30 and 21 are buffers reading then writing 64 words so one can be filled while the other is playing.
Node 20 plays sound from alternate buffers to a digital pin using pulse width modulation.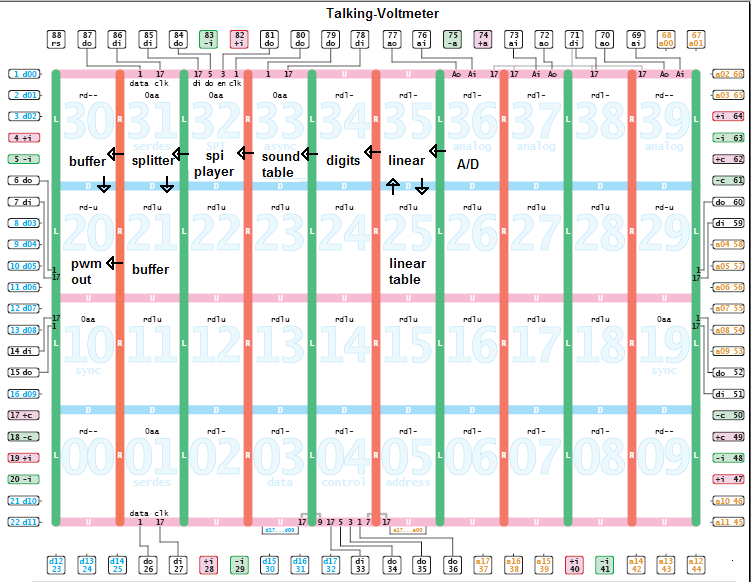
Here is a portion of the associated VentureForth code. This code was written by hand but could be generated by dropping forthlet library routine and arrow icons onto a layout diagram in one of the tools.
36 {node $171 '--l- V.APP +include" a-d.f" node}
35 {node '--l- 'r--- '-d-- V.APP +include" linearize-interpolate.f" node}
25 {node V.APP +include" a-d-table.f" node}
34 {node 'r--- '--l- v.APP +include" digits.f" node}
33 {node '--l- 'r--- v.APP +include" sound-table.f" node}
32 {node 'r--- '--l- v.APP +include" spi-player.f" node}
31 {node '--l- 'r--- '-d-- v.APP +include" splitter.f" node}
30 {node 'r--- '-d-- v.APP +include" buffer.f" node}
21 {node '-d-- 'r--- v.APP +include" buffer.f" node}
20 {node 'rd-- 'iocs v.APP +include" da-pwm.f" node}
One has to preload the compiled sound files into the SPI Flash so that it will speak out the digits
of voltage on the pin in the demo. It was a combination of two tutorial demos I saw for simple embedded systems.
It shows how one might factor a simple application. I found it useful to have a talking
voltmeter that I could use while watching something else. I should bring in an S24, S40,
or S32 version in and show it at SVFIG sometime.
5/13/09 Left-brainer, right-brainer, mid-brainer, no-brainer.
I mentioned some of my thoughts about whole-brain activity
while programming and was asked to give more detail and to
explain how I came to make the observations about the focus
on written language in our historically left-brain dominated
culture and the reintroduction of more right-brain thinking
in the twentieth century. I have talked about my history and
my opinions before but let me provide more detail on the
implications that language processing takes place in the left-brain
on the mental activity that takes place when using different
programming languages.
My first exposure to college at the University of Iowa and
at Northwestern University was when my interest was in spoken communication.
I did well and felt that becoming nationally ranked served me well later
in life when I became a teacher and later a computer consultant
to big corporations and needed to communicate with other people.
But my interests in speech, speech recognition and the relationship
between speech patterns and perceived psychological responses was
only part of my interest as I was interested in how computers could
better communicate with humans using speech. I programmed my first
voice recognition and response systems on one megahertz microprocessors
with little memory back in the seventies. So I also needed to keep up
with reseach in speech, hearing, and language processing.
I took profile tests in college and was told that I was in a
small group of right-brain thinkers who tend to see bigger pictures
than most other people. I felt that my studies in comparative religion and foreign cultures
helped me to better understand people and also served me well in later life giving
me a broader understanding of why people think what they think.
Training in arts with a physical component helped keep me healthy and
interacting with tens of thousands of other people around the world.
The math and science studies led to engineering work starting with
the first microprocessor and later to doing work like designing hardware
and software optimized for AI. That really forced me to spend more time
looking at research in neuroscience explaining mechansisms for language
processing, image recognition, and hearing, and simulating the
algorithms on digitial computers. Consider the trans-cranial magnetic
stimulation experiments that shown how language use supresses vision,
memory, creativity and other functions that take place on the right side
of the brain in the context of the endless left-brain processed
written text message discussions of programming languages on
usenet that go nowhere.
As we get older and more experienced we tend to see connections
between things that we didn't understand when we were younger.
In my case I had spent years teaching and had taught
microprocessor programming in college. I had also been assigned to
teach Forth to people by its inventor, Chuck Moore, at a number of
different companies and learned from that experience.
Because I had been studying the art, teaching the art, studying
the teaching of the art, and studying research in brain function
for making better AI designs I connected up some things that I
had experienced and came up with some theories about the often
observed problems of communicating about Forth programming.
Communication on that subject is not as simple as one might think.
My background in teaching, teaching college, teaching martial arts,
teaching Forth, and working with its inventor for twenty years on
Forth hardware and software is rather different I think than many
other professional Forth programmers and that of Forth hobbiests
and that of non-Forth programmers. My experience in researching how
humans process natural language, how language limits thought far more than
in the linguistic way suggested by the Warf-Sapier hypothesis got
me thinking about how thought in computer programming involves use of
different parts of the brain, not just the language parts.
A lot is known today about the location of specialized areas of
the human brain. We know where language processing takes place, and
of a balance between our use of neuronal processing of language
structure and our use of something more like lists of language
rules. Our DNA predisposes different parts of our brains to organize
in different ways and to specialize in function. We even know
of differences between the hardware in the language processing
area in the brains of humans and gorillas that allow humans to
have dependent clauses in the syntax of their language. Marvin
Minsky described this as not unlike a context stack in a
computer used in multitasking. He said that gorillas don't have
this stack and that theyt can't process dependent clauses in
their language. If you say to a gorilla that, "The man who
climbed the mountain wore a red hat." The gorilla is likely to
ask you, "Who wore the red hat?"
I very much liked the work of Marshall McLuhan in media studies
in the sixties long before it became fashionable. He pioneered
multi-discipline studies that challanged many people's thinking
at the time. He observed the decline of literacy in literate
cultures and said it was due to a shift from the (left-brain
language based) linear sequential thinking of the previous age
fostered by the printing press and assembly line to a more
holistic (right-brain based) point of view fostered by
electronic media. The telephone, the radio, and television
all had their own messages and effects man and on world culture. McLuhan
predicted that the personal computer, the Internet, and Google
(though he didn't name them in the sixties) were going to
continue to change world culture in the future. I highly
recommend the film McLuhan's Wake.
He said we lived in a world dominated by left-brain thinkers.
He offered right-brain ideas. People who couldn't get out of
left-brain, language based thinking, had much trouble understanding
what he was saying. And he used this to make his point to the
people who could see that when he answered left-brain questions
with right-brain answers, even when he explained that that was
what he was doing, that people couldn't get it until they engaged
their right-brain. It was easy to see in other people.
When someone is doing left-brain thinking their left-brain seems
to regard with suspicion right-brain activity, the left-brain
wants to stay in control rather than give up time to the right-brain.
The left-brain tends to classify activty that takes place in the right-brain as
emotional, illogical, or religious in nature to stay in control over
the right-brain. Right-brain ideas often involved simultaneous parallel
connections while left-brain language processing is sequential in nature.
When someone working in left-brain mode gets exposed to a right-brain idea
they may try to linearize it and fail. If they can't superimose the parallel
idea on top of linear thinking they may say, "I don't follow that!" t
I was thinking last year about why it is so hard to explain Forth to
some people and why it is so hard for some people to understand what
seem to basic concepts to some other people. I am not addressing someone already
being able to read and write, understand Boolean logic, number bases,
analytic geometry, trigonometry, algebra and calculus or having experience
with computer concepts like addressing or instruction sets and registers.
I am addressing the language and non-language issues related to the
art and science of programming of computers, understanding what people do,
and the modes of thinking about problem solving outside of all language issues.
The most obvious example of language constrained thinking is when people
engage in extensive programming language syntax comparison discussions. That
sort of thing makes Forth nearly impossible to understand. When one frames ideas
around syntax one might easily conclude like the inventor of COBOL that Forth is not a
programmming language at all because it has almost no syntax.
When comparing the syntax of two programming languages one can only compare
things that they can have in common. What is interesting is what they don't
have in common. Programming languages are designed to
do different things and work in different ways. Some have little notion of
real time or of different time phases in the development process. Some have
little notion of actual hardware while others do. Many languages assume a
minimal amount of hardware and some need more than others.
Many programming languages are designed to help the programmer keep
their focus on left-brain activity within the specific context
of matching solutions to fixed language syntax. This requires that one
assume a lot of assumptions about that context. Assumptions always assumed
become so commonplace that people no longer notice them at all.
McLuhan used to ask people, "Do fish notice water?"
When doing left-brain language syntax fitting type thinking one is not able
to do as much with the right-brain. It is the right-brain that steps
outside of language syntax limitations and assumptions about specific context.
In the martial arts you are well aware that not all intelligence or action
is langauge based. You also know that language based thinking
comes at the expense of use of other functions and other parts of the nervous
system. I can think of many lessons and many stories about language interfering
with the here-and-now.
Engage in language processing for just a moment at the wrong time and
you are dead. Think of it as you should as that moron in the car next to you
who is trying to do texting on a cell phone while driving. You don't want
to be that moron.
Here is a an example of a small shift away from left-brain syntax processing
in programming. This is someting that I have written many times and
wondered if people understood what it meant with regard to language
activity in the brain and its relationship to other brain activity.
Colorforth transfers responsibility in the brain for the recognition of some
structural components of software and specification of time phases
by representing them as color or something that is not recognized
by the decoding of strings of characters in lists, an activity which takes place in the
left-brain. One effect of this is that it unloads some left-brain activity
freeing up more finite left-brain power for other symbolic, proceedural,
and list based activity while programming. Another effect is producing less interference
with right-brain activity. After doing it for some time you can feel it.
But 'feeling it' is also right-brain activity that isn't experienced
in the left-brain and may even sound like nonsense to a
left-brain dominated thinker.
With the old essay about
"thoughtful programming" one might
think I advocate only left-brain programming. But one might also
note that I wrote
the blog entry
about why doing colorforth sometimes feels more like playing tetris than it
feels like programming. Reflexively reordering falling
colored blocks uses a very different mix of parts of the brain
than does parsing character strings for words in a list. It
was designed to be engaging and fun just like Tetris.
This is not the sort of thing the left-brain
normally concerns itself with, getting the idea requires
right-brain activity and when people are completely focused on language
or language vs language vs langauge in the left-brain they are
unlikely to see what the right-brain is capable of seeing when
it is active.
Even when given explantions multiple times when people stay
in left-brain language analysis mode they don't see bigger
picture issues that are processed in the right hemisphere.
It makes it past the ears but not the left-brain.
Do some left-brain language analysis and logic. Syntax
is language related, left-brain. Some programming languages have fixed syntax and
you can't change it or you are not doing that language. You have to
adapt anything and everything you do into the syntax of that language
or it can't be done. Sometimes you have to create a new restricted
syntax language for each new problem domain and leave the language of
the system behind when using a fixed-syntax programming language. Things are
different with extensible programming languages.
Not all forms of intelligence are related to language. There is spacial
reasoning for instance which does not take place in the same location or
with the same circuits as language activity. And the brain is both a
cooperative and competing society with an ever shifting balance of
left and right-brain and reason, emotion, reflex, sight, sound, touch,
language, reason, imagination, etc. When language is very active other
forms of intelligence including spacial, visual, immersive, emotional,
etc. are diminished. Poetry excepted of course since it is about
engaging the whole-brain in parallel ways.
Is Forth more like poetry than many other programming languages?
Many people say so. But that sounds like right-brain stuff to me.
Just as Forth is much more than just a language, as a language it is
about semantics and very unrestricted by language syntax. Language
syntax restriction is left-brain and Forth does not require as much
restriction to fitting ideas to a fixed language syntax as other
languages. There are more parallel semantic links active in the
brain. Syntax is more sequential and more specialized.
To the right-brain the big picture is important, the programmer is
a human being with thoughts other than left-brain language syntax
restricted thinking. Some languages are designed to let managers
treat programmers as standard language manipulation components.
Most right-brain activity is not part of the programmer's job
in that context, that's the idea. More is assumed to be
unchangable and focus is on smaller parts at one level of
abstraction that assume context. Yes, assume all the
context without thinking about doing that. Thinking about
the assumptions would be a distraction there.
The idea is that if many programmers are going to be used as
replacable parts to do the left-brain jobs that management
takes over the right-brain jobs and programmers are directed
not by their own right-brain but by other people's right
brain activity. Their left-brain is free to think that
right-brain activity is irrelevant to what they do if
they do that kind of programming.
To shift from the narrow left-brain context of a programmer
to the bigger right-brain picture of the social interaction
issues taking place consider what's called "Freedom from
Choice." Many people find it comforting to let someone
else do all the important right-brain decision making for
them because following is easier and because they won't need to feel
responsible for the hard decisions. It is part of
larger social trend and it is very understandable that
when you ask people to look at it that they are likely
to have a strongly negative emotional reaction to either
this aspect of social interaction or to discussions about
it.
Big picture context is mostly right-brain activity and we
can consider some issues regarding it. We could classify
questions and answers as being more right or left-brain
based on where the type of brain activity required is
taking place.
Consider from the left-brain vs right-brain thinking
perspective in the classic dialog with a person who uses
"C" and likes the way it lets them focus on one function
at a certain level of abstraction. With experience
the programmer may be inclined to step outside the narrow focus
of only high level abstracted code and leave "C" to
code some parts of the system in the assembler that
is appropriate for a more specific context. But that's
leaving "C" for assembler and I am making the point that
the idea in "C" is a layer of abstraction to allow the
job to be standardized left-brain symbol stringing
while fitting things to the rigid syntax of a
programming language.
Many "C" programmers will say that they like being able
to stay focused at the level of abstraction where
selecting the appropriate hardware, selecting the
appropriate language and compiler, selecting the
appropriate OS,
and selecting the syntactic restrictions to be used when
they fit their solution to the assumed restrictions is
all done by other people, it is not their problem.
They call it 'portability' and the idea is that
the right-brain stuff gets done by
others and they can focus just on programming the
remaining left-brain stuff.
They complain that the problem with Forth
is that it forces you do deal with both high level
and low level details, left and right-brain stuff,
abstract and detailed stuff. They want someone
else doing the right-brain stuff and the computer's
optimizing compiler to do the low level stuff so
that they can remain focused on left-brain language
syntax issues. They prefer the freedom to not have
to do all that right-brain and low level type stuff.
Just let them program!
Then the Forth programmer says that they like having
the responsibility to act as the systems analyst and
like stepping back to deal with big picture problems.
They like this because often this is how
'cancelation' happens and how one 'avoids problems that can't
be solved easily' and where they eliminate as many
non-essential parts of the system as possible. But now they
are talking about stuff that sounds like nonsense and
outside the other person's assumed context about what
is good about programming.
To people only exposed to OS written in "C" and other
languages written in "C" running on processors designed
to run "C" things outside this "C" hosted world might
not even seem like they exist despite the fact that
the vast majority of computers in the world don't run
"C".
The Forth programmer says that they like like having
very little syntax in their way, they like being able
to choose syntax. They like being able to choose how
the internals of their OS, their compiler, their editor,
and all their tools work. They like that it can all
be clearly in one simple language with minimal syntax.
They like that it is small, on a human scale, and
doesn't require a team of thousands each looking
at only a tiny part of the picture.
The Forth programmer says that they prefer to use a
system designed to satisfy the needs of the whole brain
and intentionally designed to be 'fun' (but fun takes
place in the right-brain!) They say that they like
the 'freedom.' They say that by stepping back and
using a bigger picture view the not only make solving
the real problem easier, but that they gain experiences
that will benefit them in the future, things outside
fitting to a language syntax, and that it is fun, and
gives them a sense of accomplishment and a satisfaction
in a job well done. It is very different than the
people who say computing today is all about how
fast script kiddies can trash out code in the
most restricted context.
When we say simple things like that dealing with 3KB
of OS GUI code written in Forth is actually easier
than dealing with 10MB of OS GUI code written in "C"
it is like we are speaking in a language that they
can't understand at all.
From the point of view of the person who wants to stay
in left-brain language syntax work and enjoys not having
to do all that right-brain stuff will not relate in
the same way as the person who prefers minimal syntax
in the language and to balance right-brain activity.
The "C" programmer may say that programming is not
about fun, it is not about how you feel, it is not
about freedom and that all that just sounds like
religion or mysticism to them not logic.
They may say that Forth makes no sense if they
have already made enough assumptions about "C"
and try to map what they hear about Forth to that
context.
To the left-brain and left-brain thinker all that big picture
thinking and right-brain activity is likely to be
regarded with suspicion and classified as outside
the scope of (language) logic. So as soon as you start
to discuss human issues involving whole brain activity
and get outside the issues of left-brain language
syntax issues the people who are comforted by staying
in left-brain activity will see it as just illogical
or religious thinking and tell you so. They can't
see it the same way as more right-brain thinkers
and that's the point. Attempts to communicate with
them are attempts to wake up their right-brain
to get it to understand the right-brain message.
Is there consensus about how the world works?
When I was a kid there were people who were
exposed to only abstracted computing in COBOL and Fortran
and people exposed to assembler on various machines.
Today it is a more complex picture but we have a couple of
generations now raised on the "C" abstraction. That's their
world view of computing, "C" centric, file centric, and
often Linux or Windows centric. There are a lot of people with a
very "C" centric view of how the world of computing works.
Their world view tends to be that they came into a world
where they were given a computer, given a language, given
a syntax, and given declarations to isolate code to a
level of abstraction that assumes the world is based on
architectures designed to run "C", and code running on OS
written in "C", and that all programming is about manipulating
strings of symbols in that context. They know about
that and that is the 'shared' context even if it more
or less excludes all but the tip of Forth. We are lucky if they
even get exposure to that. Those who spread their exposure
happily over thirty languages or more in that sort of
multi-language nightmare enviroment are not
going to get exposure to much of the whole brain
thinking behind Forth, or even any in depth
exposure at all to using Forth that way.
It is not like we don't see a right-brain reaction from
"C" programmers towards Forth. Emotion, and anger is in
the right-brain and we see it when Forth competes and
wins against "C" in systems where size, cost, and
power matter most of where "C" could not simplifiy the
problem enough to reach a solution at all.
The world view of traditional Forth programmers is somewhat
different than that of programmers working inside a
very different set of language restrictions.
To them it is good to have minimal language syntax
restrictions to start with and that it is good to fit
the hardware, fit the language, and fit the syntax of a
solution to problem on a case by case basis. It is good
to have the freedom to change all those things that you
can't change in "C". It is good that no OS is appropriate
for all problems. It is good to be able to step back
and remove unnecessary things to get to a good solution.
It is good to refactor after you factor, factor, factor.
But this knowledge is not shared with a couple of
generations of programmers raised on "C" systems and often
herded into even more restricted niches of this "C"
programming world, like Perl and the
scripting kiddies. Unlike Forth programmers those people
routinely tell everyone that
personal computers have infinite power and infinite
resources and that no one cares about program size,
speed, efficiency, or even clarity any more, just
about cutting and pasting from abstracted libraries.
That's what they have been taught!
I also should say that that sounds more like what the
psychologists who sell SUV say is the market pitch used to
defeat people's upper brain activity completely and get them to
respond at the reflexive reptile brainstem level. Bigger
reptiles eat smaller reptiles and use personal computers with
infinite resources. There are left-brain ideas,
right-brain ideas, and reptile brainstem ideas.
The issue of how marketing of bigger as better is done and how it
effects people's perception is also pretty much outside the
common and endless programming languge syntax comparison discussions..
It can also be noted that it is not the "bigger is better" and
"it has to be programmed in C" narrow thinking that leads to things
like processors that are smaller, cheaper, and lower power at the
same level of performance than what is possible by going down
the bigger is better "C" path.
Most people who don't share any of the experience in the
sort of right-brain activity usually involved in Forth programming
tend to mistakenly classify people's enthusiasm for that as
just religious thinking. But this is common in how left-brain
tends to classify right-brain activity not just how "C"
programmers and John Dvorak see Forth.
It is always hard to
communicate effectively with people who do not share your
world view. But there would not be much point to
communication if we all agreed about everything. The
idea if often to expose people to a point of view that
they are not familiar with. I remember what it was
like to think like a Fortran programmer before I learned
to think like a Forth programmer. I remember what
I thought before I tried teaching Forth to a couple
of generations of students.
The bigger picture here, the simpler picture, is that
left-brain activity can't understand right-brain
activity but right-brain activity can understand
left-brain activity. I am constantly looking for ways to
get right-brain ideas to left-brain thinkers, but
sometimes kickstarting their right-brain can be a
problem.
For people seeking 'freedom from thought' by sticking to
left-brain activity and letting others do their right
brain decision making for them, and for people seeking
to become a common commodity programming component in "C"
"C" is more than a good thing.
For people seeking more freedom of thought,
freedom in programming, and who enjoy having to take
the responsility for doing more whole brain thinking
Forth is a good thing. People are not all the same.
Sure, left-brain dominated thinking is more common in
educated society than right-brain dominated thinking today.
Creativity is right-brain thinking and is less common today.
The issue here is not which is more common, we know
we live in a time of left-brain traditions and a
resurgence of right-brain thinking.
The left-brain traditions worked for a long time.
The fact that the majority of people today prefer
freedom from thought makes directing them as a group
easier. But we still need a minority of people who
can do creative and whole-brain thinking.
Generally to make something 'more popular' means selling it as
offering more freedom from thought anyway or by appealing to
the lowest levels of the reptile brainstem. We live in a sea of
messages about how we can buy a magic bullet that cures everything.
People who like the more realistic view that Forth requires more responsibility in
exchange from more freedom don't think that trying
to remove the need for thinking for everyone is a good thing.
It is not Forth that is being sold as a magic bullet.
But thinking can't really been removed anyway, it
is just that some people will prefer to own the
responsibility for all the (right-brain) thinking and do
so by offering other people freedom from thought.
If you are selling that, or if you are still high
on the sales pitch from the most recent purchase
of that and still repeating the sales pitch then you
are likely to have a negative emotional response to
the idea of "freedom of thought" in this context.
When you suggest to others to use their right-brain
they may regard this with suspicion or even argue that
you don't want them to think at all. (If they are
locked into left-brain and you suggest that they
should stop using the left-brain and try the right
brain they may regard this as the same as your saying
that they should stop thinking!) They may think that
what you said was that they should just follow since
they think you told them to stop thinking instead of
expand their thinking outside of limited syntax
restricted thinking.
These different types of thinkers have trouble communicating about
many things not just about programming language issues because they start
and often end with such different perspectives about
how the world works and what is good or bad in it.
I could just make up some informal rules-of-thumb regarding more
left-brain or more right-brain activity involved in programming:
A language that has more language syntax is more left.
These rules of thumb are not hard and fast (left-brain)
but do have long chains of (left-brain) logic behind
them and could each be the subject of much discussion.
It should be pretty obvious which computer languages
were designed to be more left or whole brain oriented
in their use. Each have their niche.
It is hard to argue that a picture where the programmer
can modify the syntax of the language and deal with
source for everything, compile their OS as needed,
compile their compiler as needed, or even compile new
hardware designs as needed is a bigger picture to deal
with than what most programmers deal with. It is difficult
to argue that a programmer who assumes fixed syntax, assumes
that black box components without source are going to work
for them, assume an OS and all that it contains will fit the
job, assume a compiler will fit the job, assume a hardware
environment and that the OS, comiler and hardware all fit
together with no problems and is focused on fitting a
solution into the fixed syntax of a fixed language in
a fixed OS with a fixed compiler on fixed hardware has
given up a lot of freedom of choice and is dealing with
a lot of assumptions about context. The reason for giving
up all that freedom of choice is to make the work more
left-brain oriented. When Perl programmers have a problem to
solve what freedom do they have to solve it? Do they
redesign the syntax of Perl? No. Do they redesign
the compiler they use or do they use standard compiler?
Do they redesign the OS they use using Perl? No. Do they
redesign the processor they use using Perl? No. Do they
still have the freedom to assume that all of those things
are fixed and just focus of fitting a problem solution
into the fixed syntax and fixed box? Yes.
On all of these measures Forth can have more whole brain
activity than most other languages. After all most
languages have rigid syntax, are not extensible, do
not metacompile themselves, are not general purpose,
do not implement the OS, have more symbols and less
freedom, are large, are for compatible large
computers, and exist
to let more programmers do more left-brain focused work
and contribute less work each to a project than what Forth
is designed to let them do. And certainly
Forth is not the only programming language to be
more whole-brain than left-brain oriented.
Of course I am not talking about people who have
other serious problems that effect the balance of
their right-brain and left-brain activity. Many years
ago much was learnd about brain activity by studying
those people. I am talking about social trends and
long term historic shifts in perspective that effect
all of us.
I think one issue in regard reaction to Forth tends
to be a right-brain issue; emotion as in like/dislike
and love/hate. When Forth was new it was said that
half the people who hear about it are neutral about it,
a quarter 'love' it and a quarter 'hate' it.
If people knew the productivity and profit margin
was really as high as it is with Forth as
the many examples where work that
could not be done in a man year of "C" was done
in a man day of Forth people would have an even
more emotional reaction than they do when you water
it down and tell them that it was man month of Forth.
early history of Forth. It isn't very safe or
easy to be completely honest about Forth. Most
people who market it have to water down everything
you say a lot if you don't want to upset or scare
some people. Other people water down the Forth
they do by not exercising most of the freedom it
offers and don't worry about upsetting non-Forth
programmer by using Forth only as debugger or
a yet another inefficient scripting language
to be used 1% of the time.
I have worked at companies where management didn't know
whether to believe the claims made by their best Forth
programmers or the claims made by their best "C" programmers
and who decided that the only thing to do was to spend
millions of dollars or tens of millions of dollars
splitting the money evenly and paying two teams to see
real results on which they could make informed decisions.
It is another thing in my experience with Forth that
is probably not shared with many other programmers
and we probably don't have the same experience about
how the world works or having seen people do in Forth
in days jobs that other people couldn't do in months,
years, or at all using other languages.
So despite this just being part of Forth history most
programmers don't want to face the truth about Forth.
Many programmers prefer negative sound-bites to
explain away Forth. That may be all many people have
ever heard about Forth. The reality of Forth history
(non-hobbiest Forth history) seems less believable and
more like nonsense to each suceeding generation of people with
experience only in segregated languages for hostile
programs and who were taught left-brain programming
methods for that narrow context that excludes Forth and
the freedom it offers by definition.
It is hard to communicate with those people because
all but Forth syntax and negative sound-bites are
not part of the knowledge that has already been commonly
shared with them, and syntax is just left-brain. Forth is
about the freedom to change the language, the compiler, the
OS or even the hardware design and is very different than
programming languages that are about fitting things to a
fixed language syntax in a narrow work context.
Forth is something that they would much rather dismiss
from what they have heard about it than understand. Forth
has so little syntax it doesn't even look like a
programming language to some people.
The most common thing one hears these days is, "I
don't want to have to deal with anything as low as
as a stack, that's why I delegate that to an
optimzing compiler. I just use a compiler I don't
want to understand it. I don't want to deal with
anything OS, that's why I use the interface. I
don't want to deal with programming an editor or
anything else other than my assignment. In my
world someone else selects the computer and the
OS and maybe even the editor that I will use.
I like a narrow focus and small picture, that's
what computing is all about today and in the
future!"
It is less common to hear, "I like dealing with the
big picture and that's why I want to understand the low
level code and want a simple compiler with optimized
source. I like programming the OS layer if I can. I like
programming the compiler if I can. I like programming the editor
that I am going to use every day if I can. I like dealing with
an integrated whole. I like having more freedom to step outside
the box to find a solution to a problem. I don't think that
one OS or one compiler can provide the best solutions
to all problems."
To Forth programmers Forth is about being correct by
design and avoiding bugs, it is about elegant and beautiful
solutions. It is about learning and knowing what you
are doing and not needing elaborate restrictive mechanisms to
protect yourself from yourself. To some Forth programmers many
other programming languages seem obssesed with making plans to perform
errors and focus on mechanisms to handle the errors that they
plan on as their practice. It seems that many people want to drag
Forth in that direction. To Forth programmers many other
programmers seem to want to make things more complicated
because they need to make them more complicated and
they don't understand the practice of keeping things so
simple that most of the errors they plan for won't and can't
happen.
I have covered a lot of ideas on history, learning, social
trends, media, brain activity, language activity vs other
brain activity, programming and Forth. Most of them are not
my ideas and are meant to frame my thoughts on the balance
of brain activity in the practice of the art of computer
programming. I expect that anyone can find some idea they agree
with and some they don't agree with. And I expect a few
people would say that it makes no sense at all to them just
as they did in the 1960s when Marshall McLuhan explained
most of the ideas before Forth existed. I liked his
explanations in the sixties of how these things would lead
to the Internet and Google searches and how those things
they mean change for the "global village."
His somewhat poetic phrases were designed to engage
whole-brain understanding of some ideas. It was funny
even back then to see people acting like he kicked them
in the head and their emotional reaction to simple to
understand phrases like global village. It was seen as
revolutionary thinking in the backwaters fourty years
ago. Now that we can see clearly in the rear-view
mirror that he saw some important whole-brain and
social trend ideas that predicted the last fourty
years so well that we can continue to let them
help guide us into a future where we have thought
a little about where we are going.
"We make our tools and after that our tools make us."
Marshall McLuhan.
"The laws of media are observations on the operation and effects of human artifacts
on man and society. They are at least a hope that we can reduce this confusion to
some soft of order."
His laws involved concepts like Enhance, Reverse, Retrieve, Obsolesce.
"The first question to ask of any technology, any tool, is what will this thing enhance?"
When you have spent decades working with someone who
invented a very unusual programming language and then
using this language wrote compilers and operating systems
and designed computer hardware optimized for
use with this language you think about that language and
its use in a different way than most people think of
their programming language. The experience in writing OS
tuned to applications and in writing compilers and designing
and debugging hardware is experience in a larger context than
what comes up in work with more left-brain oriented programming
languages especially when in a loop influencing hardware
design and software design generation after generation. Although natural language limits thought artificial
languages, programming languages, limit thought far more.
McLuhan said, "It's translation. It's a loop. You shape your
tools in your own image and in their turn they shape you."
When you see a programming language evolve and being used to design
hardware to execute the language you can see the step by step
process through the loop. Using the language changes your ideas.
Your new ideas lead to new ideas of how to make the language
more efficient. These lead to ideas on how to make the hardware
more efficient. It's a loop. After seeing the loop spun a hundred
times and understanding the very long chain of logic in the
reasoning and experimentation to learn the unknown the evolution
in the loop is obvious. The loops in the big picture are obvious.
Some people will claim that
there is no such loop in programming, that software is not influenced
by hardware design and that hardware design is not influenced by
software design. Despite the fact that designers at Intel said
very clearly that they made changes to improve the performance of
"C" code once their machines got big enough to host "C" systems like Unix
so long ago many people have not been able to see the loop there has been
in PCs where software has been influencing hardware design and
hardware design has been influencing software design for decades.
My take is that understanding that loop helps understand Forth.
PCs are designed to run hostile software because they are designed
to support "C" and popular operating systems with many of the same
"C" system components. The idea originally in "C" was for multi-user
minicomputers where one user's program may be hostile to another
user's program. The whole idea is about a central control authority
to police weaker potentially hostile user processes and misbehaving
or buggy software.
Forth happened about the same time as "C" and was first noticed
for being smaller, simpler, having better real-time performance,
and being able to support more users on that same hardware. It
as able to simplify and speed development software and simplify
run-time requirements for the OS and application programs. Part
of that simplicity was about how it was debugged and made cooperative.
When you take Forth out of Forth source, out of a Forth OS, out of
a cooperative software environment and drop it into a "C" system
as hostile software you then have to deal with many "C" notions
that Forth was designed to avoid. But the thing that is hard for
some people to see is that you have to make so many assumptions
in the first place to take this path. After a while they not
only don't question those assumptions, they don't notice them.
McLuhan said, "Narcisus was drugged into thinking that that image
outside wasn't himself, it was somebody else. Narcisus did not fall
in love with his own image, he thought it was somebody else. And
the same with us with our electronic technological gadgetry and
gimicry and so on. We don't think that that is part of our
physical organism extended out there. We're like Narcisus,
completely numb."
He said, "Now when we put out a new part of ourselves, extend
ourselves with technology into the outer environment we
protect ourselves by numbing that area. The more I looked at
this the more difficulty I had in explaining why people ignored it."
McLuhan was a man who tried to communicate many right-brain ideas
to the rest of us. He used sound-bites. "The medium is the message."
He tried to kick-start some people's brains and sometimes it worked. Other
times people ducked and ran for cover or saw it only from the left-brain. McLuhan took
things his students thought they already knew and made them take
closer look at things that they took so much for granted or were
so numbed to like the advertizing messages that had been all around
them all their lives.
To quote the film, "He showed them that they didn't know it and
that they didn't pay attention to it. And if they could pay attention
to it they realized that their brains were already being massaged
and that they were oblivious to this environment even at the same
time that they were being almost robotically conditioned by
this environment." I have felt the same way about how people
are numbed to their ideas about programming being manipulated.
McLuhan wrote in the Mechanical Bride, "Advertizing is a vast military-like
operation ultimately and brashly intended to conquer the human spirit. The
advertizers manipulate our heads. He plays around with human beings like
we are his private pigment. He smears us. Students and historians in the
future will pour over our advertizing world with the sort of intensity
that we should long ago have directed to it."
I feel much the same way about the programming that gets sold
and about what we teach kids in school, what they take for granted, and how
it influences their thinking or lack of it.
The medium is the message there too. And as McLuhan saw long before most
people new tools, the personal computer and later the Internet were going
to change people in new ways just as TV, radio, the telephone, the
printing press, the written word, and the spoken word had changed what it
meant to be human before. "The laws of media are observations on the operation and effects of human artifacts
on man and society. They are at least a hope that we can reduce this confusion to
some soft of order."
His laws involved concepts like Enhance, Reverse, Retrieve, Obsolesce.
"The first question to ask of any technology, any tool, is what will this thing enhance?"
"The laws of media are observations on the operation and effects of human artifacts
on man and society. They are at least a hope that we can reduce this confusion to
some soft of order."
His laws involved concepts like Enhance, Reverse, Retrieve, Obsolesce.
"The first question to ask of any technology, any tool, is what will this thing enhance?"
You can't express the message of one medium in another medium and I am
writing text. But if you are reading it you are probably using a PC and
the Internet. You can't always express the same thing in different
languages but I would characterize the 'message' in the Personal Computer
medium as having changed a lot from the first generations to today's
Internet access and movie and game playing machines.
The first personal computers were imagination machines. The next generation
were secretary's tools. The next generation were dazzling as toys or as
resources linking people around the world like one big nervous system.
As this process has taken place the message the users got in each
generation of machines was different. For a while the right-brain imagination got
wrung out and was replaced by practical left-brain tools like speadsheets
and word processing programs and databases. This was part of marketing
the machines, making money, and messages being sent by the manipulators
were automate, use fewer low earning people to get more work done, if you
are a low earning person get more work done with automation, buy more
Personal Computers and software, be better than the Joneses, consume
and enjoy.
Advertizing has to be one sided. As Jeff Bridges said playing Preston
Tucker in the film Tucker a Man and His Dream, "If you are selling
candy you say it tastes good, you don't say that it rots your teeth."
The message in PCs has had to have a filter about certain content.
I think of the PC industry much the way Tucker did about the
auto industry in that film. There are a lot of things that should
have at least qualified for prosecution of criminal negligance.
There must be a lot of people who agree with me. Intel was just
fined 1.4 billion dollars today in Europe for unlawful practice.
One strategy to deal with the PC content filter was to spin negatives as positives. Much
of the PC industry is about dealing with the problems that are put in
to be able to be easily improved. Many software products depend on things
being absurdly buggy. On the last few new PC on which I installed software
one of the first things I did was to load software to remove registry
errors and spyware because accord to it the PCs come with dozens or hundreds
of dangerous and malicious spyware programs installed when you buy
them.
There have been two counteracting forces in the PC messages. The increasing
complexity of PC hardware and software has made them intellectually impenetrable.
This has turned them into what we call black boxes, like television.
People could only specialize
or deal with the outer surface. Imagination and creativity were fostered by
the first generation because they were understandable. The marketing
direction has been to foster left-brain use and that's what we have
been teaching in the schools not the right-brain creativity.
Competing with that the Internet has been a strong factor for
society to spread right-brain ideas. Though the mechanisms for verbal
and written communication are left-brain we can also use pictures,
movies, sound, music, and objects that interact with a user to
engage the left-brain or right-brain.
The internet offers more than access to textual content and more
than multi-media content, it also offers several different communication media.
Yes it is used to market things for sale but it also offers
different messages than just the marketing information to
buy more PCs or to buy into the lastest fashionable software trend.
The message on this page is expressed through Internet content and is
Internet content but it also contains messages that are different than
most other and quite different than that messages that have to censor
questioning any of the assumptions about how things are or have to
be that people make without even being aware of it. The message
here is also about how I see things and how I came to the conclusions
that I try to express here about the patterns
that I have seen over the years.
More than a decade ago I asked Chuck if I could do an interview
with him about Forth style. In the process he named his presentation "One times
Forth" and explained that ideally Forth compresses a problem and
solution description to a minimum form. This approach matches
his comments that Forth is more of an approach to solving problems
than it is a programming language.
In studies of Complex Adaptive Systems the Nobel Prize winner
Murray Gell-Mann forwards the concept that complexity in a system
is measured by the length of a complete description of that system.
Chuck Moore has applied his system of solving problems to Forth
software system design for more than four decades and to hardware
design for more than twenty-five years. Gell-Mann says that for
every system the minimal complete description measures the essential
complexity of a system. This matches Chuck's notion of "1x" or
"one times" essential complexity in Forth.
Gell-Mann says that adding non-essential details to the description
of a system creates a description that is larger than one times the
essential complexity. He calls this the effective complexity of a
system. Chuck Moore's approach to solving problems begins with
analysis of a system and ends with a description of the problem
and solution ideally as one times its essential complexity.
My own experience in writing system code for ROM on SEAforth
chips reminds me of a rule of thumb that Chuck once quoted which
was that anything which can be expressed in a thousand instructions
can be expressed in one less. He was half-joking when he made that
comment, he was saying that one times minimal essential complexity
is an ideal and approaching it yields diminishing returns on effort.
He had said that everyone seemed to agree that Forth had its
greatest advantages on systems with constrained resources and
he was designing a processor with resources so severely constrained
that Forth was the only thing that would fit. With a version of
machineForth finely tuned for parallel use with synchronizing
communication ports between processing nodes programs code now had to
fit within sixty-four words of memory. So the new variation on that
rule of thumb became that any program that can be expressed in sixty-four
words of code can be expressed with one less word.
My first programs were suppose to fit within sixty-four words of
ROM. It took some effort to factor some of the required functions
into expressions that allow it to fit. But as I continued to work
on the code what had taken sixty-four words got compressed down to
fourty or fifty words and more functions were fit into ROM. And
when I had some function honed down to fifty words of memory I
would begin to think it was close to 1x until some senior Forth
expert would look at it and see how to save a cell of memory that
I had not seen. Code that I thought was close to 1x was shown to
be bigger than that. Often I might then see a way to save another cell
of memory that they hadn't seen in their vision of 1x.
At this stage changes tended to only yield one percent or less
reduction in program size. But improvements of one percent
at a time did accumulate this way. It was always very difficult to
find a place to save a word in Chuck's code as he would try harder than
other people to get his code closer to 1x.
One simple rule of thumb that I have found is that one can get a
good estimate of how close something is to 1x by how much effort it
takes to compress it. If it is easy to remove non-essential complexity
and make it smaller then it is not very close to 1x at that point.
If it is very hard to find non-esssential details to eliminate it is
approaching 1x.
Chuck's explanation of one times Forth went along with his explanation
that Forth is more of an approach to sovling problems than a programming
language. Our left
brain dominated culture biases our brain activity with language.
But it also shows that use of language processing in the left-brain
will as a consequence prevent right-brain function. In experiments where
strong magnetic fields prevented left-brain language function the right
brain functions are shown to increase. The big picture point of view,
spacial reasoning, and art and creativity among other things are performed in
the right-brain. Older and faster reflexive brain functions that developed
before human consciousness and which may be located closer to the brain stem
are suppressed by left-brain language and procedure driven activity.
Some arts cultivate whole brain use precisely because the cultivation
of left-brain language dominated thinking limits other aspects of
human intelligence. The purpose of training in certain arts
is to allow more whole brain activity where a more useful balance of
left and right-brain activity encourages creative and personally
rewarding activity. The top level of performance in almost any art
is accomplished in whole brain activity described as "natural" or
"in harmony." Cultivating ideal natural behavior requires considerable
effort because of our exposure to our habitually left-brain dominated
modern culture.
Forth requires seeing a big picture. Seeing a big picture is right
brain activity. Using appropriate proceedures or applying language
to a small picture is left-brain activity and happens only after
the right-brain determins the big picture and context. Using the left
brain for langauge can impact the ability of the right-brain to see
beyond language issues. But seeing beyond language issues is an essential
feature of Forth as described by its inventor as a system for solving
problems precisely because it requires seeing the big picture from the
start.
Forth's inventor says that Forth includes creativity and that Forth
includes fun. He says he doesn't see these as high in the design feature
list of other languages. Creativity and fun are right-brain functions and
most computer languages are very left-brain oriented.
Part of the big picture is that there is a human with a problem to
be solved and a solution involves computer hardware and software. What
is obvious to whole brain thinkers and outside the reality of left
brain thinkers is that language is part of the problem, that language
adds some essential complexity to the complexity of the big problem. In
the Forth problem solving approach to solving a human and computer
problem you first have to start with the right-brain big picture
thinking before you descend into left-brain language semantic or
syntactic issues. Forth starts with various whole brain thinking before
it gets to computer language.
In embedded systems the big picture issues are often related to
the volume multiplication factor. Because intended volume is large
the goal is to get all costs as close to zero as possible. The
number of transistors used in the hardware is related to manufacture
cost. The size of software used relates to the required amount of
memory and effects system costs. Size effects power use which
effects power system costs. These things are abvious to the right
brain and it calls the left-brain to perform the exact calculations
in that context.
left-brain only thinkers who never engage their right-brain see
all computing environments as infinite in size and without constraint.
They labor under various misconceptions and repeat non-sensical phrases
such as, "No one cares about efficiency anymore. Computers are cheap.
Anything can be expressed in any language."
The first job the right-brain assumes is context. The first thing
the right-brain will see is the scale of the problem, the size of a
description of the problem and solution. The right-brain will
eventually use the left-brain to work out the details of size as
these are part of the real big picture. The first decision the
right-brain usually has to make is, "Is this a fit?"
The notion that any language can express anything misses the bigger
picture of the real world where size constraints trump language
issues. By count most computer systems are very small and preclude
the use of just any programming lanuage. Only in a world where size
isn't a constraint and time isn't a constraint is the notion that
any language can express anything true.
The Warf-Sapier Hypothesis that langauge limits thought is but
the tip of the iceberg. Language often prevents thought, some
languages more than others.
left-brain thinkers like to examine the place where languages
overlap and do comparative language analysis. Forth is more than
a language and as a language it is mostly about describing problems
and finding solutions that are not accessible with other languages.
For the most part that means that in practice comparative language
analysis is useless because it simply misses the big picture which
says that the big part, the important part, is where lanuages are
mutually exclusive, not the small part where they would overlap in
an unconstrained dream world.
Do some right-brain thinking. The original paper published in Forth
in 1968 stated that the purpose of Forth was to avoid the "multi-lanuage
nightmare." Comparative langauge feature analysis is part of that
multi-language nightmare, you have to pick the best specialized language
out of a list of dozens of languages for every problem where the fixed
and non-extensible language of the operating system is weak.
The original paper implied that Forth sought a minimal description
expressing the essential complexity of a problem, and a problem
where the a human seeks a solution to another problem. Part of the big picture
issue is the responsibility of the programmer to see how the human
and use of language effects that picture. Part of the big
picture is for the programmer to recognize the observer effect and
the presence of a human mind in the problem. This can be seen in
Chuck's approach to always first try the thing that everyone else
will reject first. It is important to remember that the biggest
constraints are only in your mind.
Part of the big picture is focus. The Forth approach is to focus
the human mind on the essential details of the problem to be solved
and to avoid non-essential details that add to the effective complexity
of the resulting problem and solution. From the beginning the idea
in Forth was to keep non-essential details to a minimum by using
only one language, Forth. Forth for the OS, Forth for the editor,
Forth for the compiler, Forth for the application. Forth forms
an integrated whole rather than having segretated layers used in
the multi-language nightmare approach.
As Gell-Mann has shown the essential and effective complexity of
these systems can be easily measured by the size of the description.
The description in the case of a computer system is the code. In
Forth we measure the size of the Forth code, that's it since it is
all Forth. In a complete computer system we have a human, a computer
with specific hardware, an OS, an editor(s), source and executable code,
compilers/interpreters/assemblers, and application(s). This is part
of the big picture and its complexity can be measured.
One times Forth says that any Forth system needs boot code and a
Forth kernel and will contain Forth source describing further problems
and solutions. One times Forth says that the big problem is the
development enviroment and runtime environment and includes human
factors, boot code, OS, editor, compiler/interpreter, and applications
and that well factored Forth code will approach a description of this
with minimal length.
An even larger picture shows that one cannot discuss software
without a hardware context and that the real picture involves
the complexity of both the hardware and the software. The big
picture says that one can measure the complexity of hardware
just like software by measuring the size of a complete description.
Chuck has applied the notion of Forth as a system for solving
problems to various aspects of hardware design just as he has
to programming and software design.
The way Chuck Moore practices Forth as a programming language
is a lot simpler than what other people who use the term Forth
do. The practice is a lot more than having new words that
obsolete much of the standard Forth kernel. The inner workings
of the compiler and interpreter have been simplified. The
practice itself is greatly simplified as reflected in the
features not present in Chuck's 1x approach to Forth that
are in common practice. Future 1x Forth design and practice
article might include explanations of details such as:
No compiler security.
This might help people understand what Chuck means when
he says that prefers simple methods to more standard ones.
A language that is extensible is more right.
A language for a specific problem domain is more left.
A more general purpose language is more right.
A langauge that can specify itself is more right.
A language that implements the OS is more right.
A language with more symbols is more left.
A language with more freedom is more right.
A language for projects with 10,000 programmers is more left.
A language on more of a human scale is more right.
A language that needs big hardware is more left.
A language for small hardware is more right.
A language that can't design hardware is more left.
A language designed for fun is more right.
If it is described by its inventor as more of a system
for solving problems than a specification for a programming
language it is more right.
2/16/09 Some Observations about One Times Forth
No stack overflow detect.
No stack underflow detect.
No use of immediate words; macros.
Use only two wordlists; forth and macro.
No use of application wordlists; cooperative programming.
Return Stack is a state-machine; built-in debugger.
Colors instead of words, right-brain instead of left.
Blue color; edit-time execute.
1/4/08 "colorforth is a lot like Tetris."
At work I write code in colorforth for CAD code
running on the Pentium and target code for target
SEAforth chips. I also write ANS Forth code for
tools like compilers, simultors, and code test
facilites on the desktop. I write programs in ANS
Forth that create more programs that generate target
programs. I write ANS Forth code for embedded
platforms in addition to the ANS desktop code.
All these things are called Forth but they have
significant differences. The differences go
deeper than things visible on the surface like
standard/non-standard, preference for
files/preference for blocks, desktop ASCII byte
file editor/integrated colorforth color token
Shannon encoded editor, qwerty keyboard mode/
Dvorak keyboard mode, etc.
For other people there are differences that are
not there for me. Some people have access to
excellent user manuals and reference documents
for their ANS Forth but they don't have
that kind of documentation for colorforth.
But at IntellaSys we have excellent product user
manuals and reference guides so there is no
difference in that regard.
But there are differences that are true for
everyone and which are probably not apparent
to those who have not made it past the learning
curve in colorforth to have colorforth experience
of writing real applications. I was thinking about
those differences the other day after doing some
work in colorforth.
There are side effects of doing things in those
very different ways and there were different design
goals in those different systems in the first place.
The inventor of Forth had said decades ago that
what distinguished Forth from languages like "C"
were a lot of things. For one he said, Forth is
word oriented at both the semantic level and at
the structure level while he said people should
accept that "C" has a more byte oriented focus.
Early Forth systems were all implemented on word
addressing machines, not byte addressing machines.
Early Forth systems often had characters that
were not 8-bit. And Chuck said that Forth was
not tied to byte access while about the first
sentance one will notice in the requirements for
the most popular "C" compiler, GCC, is that you
need byte addressing. And of course there is
the assumption in "C" that source files will
be bytes and will use the Operating Systems
file system and file system utilites when a
developer is using "C". These were not the
assumptions behind Forth.
When the desktop market expanded developers
embraced the assumptions used by "C" programmers
and needed to adopt Forth to these environments.
So they looked at what had distinguished Forth
from "C" in the past, two stacks instead of one,
no need for locals for with two stacks, use of
blocks for source instead of "C" file system
"C" style source code and "C" style source
code editors, small systems with integrated
OS services written in the language instead
of large systems with large interfaces to
the "C" program API to "C" OS services and
said, "those are the problems in following
"C" to the desktop."
So to make Forth 'portable' in the "C"
definition sense of 'ports to "C" systems'
instead of the 'Forth in Forth is the
easiest thing to port' meaning of portable
a decision was made to create a new Forth
standard that would give up Forth's second
stack, observe that without a second stack
that locals become imporant like in "C",
give up on source in blocks for source in
"C" style files and "C" style file systems
access to "C" OS interfaces, and to build
large systems easily integrated into "C"
environments or even written in the "C"
language in the first place instead of
being written in Forth.
There were other reasons for the great
split in Forth history. When Chuck Moore
made the lateral move from Forth Inc. to
Novix, the other company owned by
the same person, to make Forth hardware along
with Forth software he said that he saw
it as opportunity to simply Forth because
he felt that Forth Inc. had developed "a
corporate culture of marketing complexity."
I had been a strong proponent of the development
of the ANS Forth standard and Chuck had attempted
to make contributions to the standard. Chuck
said all his contributions were sumarily rejected
and that he concluded that a standard carefully
drawn to exclude him was not intended for his use.
Years later when asked why he had given up on
Forth for a few years and tried the sourceless
approach he said that his deliberate exclusion
from the standard and the result of the politics
of the committee process was so bad that for a
while he gave up on the language that he had
invented.
And his sourceless programming era was in a
sense part of the same effort that led to
Forth where the idea of less source code
was tested. The sourcelss experiment was
to determine whether going to the minimal amount
of source code, zero, was a useful thing.
He eventually concluded that it was not,
explained the reasons and returned to Forth
in 1996 with the introduction of the first
colorforth.
The inventor of Forth continued to go in the
direction of his original ideas that
the power of Forth is in its simplicity and
that two stacks instead of locals and blocks
instead of files and words instead of bytes
is what had distinguished Forth in the past
and should continue to distinguish Forth
in the future from things like "C". He
had designed word addressing Forth chips
for over a decade by this time and has
continued to do that for more than a decade
since and has written word oriented software
from the beginning.
He saw that if he updated the inner loops
of the command interpreter and the compiler
from what he had written thirty years earlier
that the compiler could become significantly
smaller and simpler and the compiled code
could be significantly faster. Simple concepts
like searching the dictionary first when
encouring numbers had been a technique well
suited to small system thirty years earlier.
He had learned that different time frames
have different costs and that it was useful
to move operations to earlier less expensive
time frames and leave less to be done in
later more expensive time frames. An
example of this was that the name dictionary
no longer had to be searched on every number
at compile time.
When I was programming in ANS Forth and colorforth
the other day I made an observation about what
I was doing and how I was doing very different
things in the different environments. I remembered
Chuck saying that one of the important design
goals of colorForth had been fun. Fun is a
difficult thing to quantize. Fun was not listed
as a design goal in most languages or in ANS
Forth. The goal there was to produce a
specification to make Forth more 'portable'
in the "C" sense of the definition of portable.
I and others had observed in the past that
the replacement of some Forth syntax with
color, and the replacement of some Forth words
with color results in a different balance in
use of different parts of the brain in a user.
The part of one's brain that scans strings of
characters and sorts out the semantics of words
is different than the par of the one's brain
that recognizes different colored objects in
a color image.
And the part of one's brain that scans strings
and uses the semantic meaning of the matched
strings is pretty heavily loaded when programming.
And I was noticing that since ANS Forth was
designed to allow arbitrarily deep nesting of
control structures in code there is nothing
preventing words and definitions from becoming
arbitrarily long other than the habit of the
programmer. Source in files also supports
arbitrarily long source code constructs while
colorforth uses blocks that factor code into
one kilobyte chucks that are presented and
edited as units.
As I was factoring a new problem and writing
code in an ANS Forth file as the file expanded
to be larger than my screen I started having
to scroll up and down to scan what I was writing
and I even opened another window so I could
look at one part of the program in one window
and edit another part of the program in another
window without having to scroll so much. I
recall thinking that this is what a lot of
people do in ANS Forth. They may even open
dozens of source files at the same time to
try to deal with this problem.
Later when I was writing some colorforth code
I noticed that it was forcing me to write
shorter routines. The code wouldn't work
if it is arbitrarily large because it
wasn't designed to support arbitrarily large
control structures. This was done intentional
to try to force the programmer to write more
heavily factored code and to help them to avoid
the problems that come from arbitrarily
large control structures in code being the
major source of bugs.
Chuck says if you make most of the definitions
short enough that you just
cannot make the same kind of errors that are
typical with arbitrarily deeply nested control
flow and arbitrarily long definitions.
We all use
the same words when talking about programming. We
all say we 'factor' our code. But some people
factor into ten page functions, some into
code into ten line functions, and some
factor code into an average of seven to ten
character functions.
I recall taking a bi-phase synchronous serial
input testbed routine and making a copy of it
to create a high-speed single phase synchronous
serial input testbed routine and making a few
changes to the new routine. As I started to
leave the block a colorful visual rearrangement
caught my eye and I moved some code around
to make the code cleaner before leaving for
other work.
But then another colorful visual rearrangement
caught my eye and and I quickly turned a colored
block sidesways and slipped it into an open
space so that it canceled out some other code
and could be deleted. A line of colored code
dropped away and the result was a much smaller
and less cluttered screen that was obviously
simply and faster code and which obviously
could now accept more code if I needed or
wanted to expand this function. When you
only have a few lines of code removing one
is a big deal. And I started to leave the
block again.
But then another colorful visual rearrangement
make itself apparent and I felt almost compelled
to turn a colored block of code sideways,
slip it in over there, cancel out that code,
and watch another whole line of code dissappear
again. I felt a sense of accomplishment again
at a very primitive and satisfying level.
The thought reminded me of Tetris and how the
reflexive turning of colored blocks as they
fall into colored spaces, cancel them out,
and make them go away, had been such a
satisfying and fun thing for people at some
primitive level that the game had been very
addictive and a wild sucess. I also remembered
how Chuck had said that his was about the
only computer game that he had enjoyed and
had found strangely addictive at a primitive
level.
I thought, "Colorforth is a lot like Tetris.
It uses that same part of my brain. It is
fun." It satisfies some part of the reflexive
brain to spin those falling colored blocks
and see them fall into the spaces and cancel
out the growing problem that the pile of
accumulated blocks getting bigger and
bigger and the free space getting smaller
and smaller. When you make the free space
get bigger and the problem of the growing
pile of blocks get smaller it feels good.
It is fun. It was designed to be fun. It
doesn't feel like work. It doesn't feel
like programming when you reflexively spin
the falling colored blocks and see the
source code compact itself and get smaller
and simpler and faster. I remember
thinking that it was as fun as playing
Tetris and that it was designed to try
to engage these different parts of the
user's brain this way to make the job
of programming easier, more fun, and
to get more productive results by
almost enforcing better factoring.
I recall Chuck once commenting that people
who say that no one cares about quality any
more but only how fast people can crank out
commodity code are wrong about Forth and
that as far as Forth is concerned there is
still a requirement for fun and for quality
and that there is a sense of satisfaction
for a job well done. That reminds me of
the fun of watching the colored blocks
spin in the air and fall and cancel out
and go away and the sense of accomplishment
of seeing the code sort of optimize itself
to be smaller, simpler and faster.
Chuck says colorforth is a really
nice Forth. If you think the "F" in
Forth stands for fun then you might agree
with Chuck about that. Colorforth was
designed to free up cluttered code and
to free cluttered minds from the problem that
arbitrarily factored code is the main
source of bugs and problems in programming.
As the arbitrarily factored code becomes
larger and larger and buggier and buggier
and harder to test it is like the pile
of blocks in Tetris getting higher. It
is stressful. It compounds the problem.
Every time you add more code to fix
some specific problem you make the problem
worse. If you can't keep up with the
growing pile of syntactically arranged
symbols it is game over. You lose.
"What you take away is more important
than what you add." Chuck Moore.
Sept 28, 2007, "Forth Enthusiasts are not all the same."
> Dear Jeff Fox,
>
> I'd be happy to hear anything about colorforth release
> features, or colorforth release dates, that has not been
> mentioned before.
I am pleased to report that Chuck remains delighted with colorforth saying it is the best Forth he has ever done. He clearly enjoys using it and seeing other people use it. colorforth has been challanged in the workplace to prove that it can be used to write code that does things that normally require software with six figure license fees. It has shown to have remarkable development times and remarkable application performance.
Chuck continues to work from a floppy based environment. He has found it difficult over the years to find new laptops that have non-usb boot floppies. Most users run from windows laptops or desktops and some have racks of computers running colorforth.
The latest release comes up with the word qwerty on the command line. That's the first thing I turn off, as does Chuck. Boy does that throw me off. I can touch type in colorforth pretty well and there is usually a menu one can glance at to keep your brain moving forward.
Things like the editor menus don't change in qwerty mode, so I can get by, but whenever I need to type a word name I have to lift up my hands and scan the qwerty keyboard to find keys because my fingers are trained to do quasi-dvorak when my brain is in colorforth mode. I tell people that it only took my fingers a couple of days to adapt to the easy colorforth keyboard instead of the years it took to touch-type in qwerty the way I can. But the need for my brain to translate from qwerty to dvorak to qwerty constantly in colorforth in qwerty mode slows me down to a crawl. So the first thing I do is turn that off.
The quasi-Dvorak keyboard was clearly designed to make it easier, and I found it did after a couple of days. But I have heard other people say that they cannot teach their fingers so they could not use colorforth. And I understand that colorforth had a lot of things that match where Chuck is going but don't match to what other people normally do (use Ascii, use qwerty, use opcodes from his chips as the Forth primitives, use color tokens etc.) It may make it easier to train some people when they can touch type word names in qwerty mode even if it is not as 'efficient' as quasi-dvorak typing. It is one less barrier to deal with.
I do like the new editor functions. Cycling through colors on the word at the cursor is nice. I think that they are waiting to have a new replacement editor all in source compatible with the new boot code and waiting to strip out the original bootstrap editor from the kernel before they release a new version.
> I would like to hear your theory on "what else might be
> discouraging people from contributing to the colorforth
> community" if you are able and willing to share here.
I think people know my opinion and I know it isn't popular in the mail list as I have expressed it before. I haven't changed my opinions on colorforth, that it is all about the big picture, forth software designing and matching Forth hardware. Pentium is a bootstrap distraction that is less than 1% of the real picture but is all that many people are focused on.
And I have said for a decade that you can't understand colorforth really without understand why it was written, the intent, and where it has been headed. You can't understand it without understanding the history and the evolution of the ideas and I still think people who jump for 30 year old Forth to colorforth without studying he history will never get it.
I see a pattern in the Forth community that is present in the colorforth community too. There seem to be two very different types of Forth enthusiasts. There are programmers, people who work with Forth systems and design/write/debug/enhance/maintain applications. To be programmers people need a working system. One percent of those people will need to spend one percent of their time doing something other than Forth programming, Forth porting. So these folks have little or no intest in the requirement that .0001 of the time needs to go into porting.
As stated in an interesting article in Scientific Amerian last year on how to become an expert in anything it takes about a decade of full-time dedicated study and work to become an expert in anything. And I think programmers who spread themselves over 30 languages would need 300 years to become expert on them. Yes they can learn a few pecent about each one and understand what they have in common. But this doesn't help much with Forth which was designed to have very little in common with these other languages. So you can learn the 1% of Forth by porting it or by using it alongside 30 other languages but no one is every going to learn to really program in Forth that way.
It is like someone who spends 30 years practicing the violin 8 hours a day 7 days a week and what they would learn seriously studying the work of masters and how that would compare to someone who taught 30 instruments in a band class in gradeschool. Yes, the person who spreads their study over 30 differnt instruments could probably play a recognizeable version of "Mary had a little Lamb" on every single one of the instruments but they could never play anything resembling the kind of music that would come from the other person.
If you ever have a chance to interview anyone who has been reviewed as the greatest violinst in the world ask them if they think that a junior high-school band teacher who can play 30 instruments equally well (or badly) understands the violin or thinks of it the same way they do. I have done it. While I haven't actually seen anyone who plays 30 instruments claim that they have a better mastery of the violin than someone with extradinary natural talent, 30 or 40 years of dedicated serious stduy, and reviews as perhaps the best in the world in what they do, but I see that all the time in Forth enthusiasts. ;-)
I see a lot of 'Forth enthusiasts' who want little more than to port Forth, most appear to not have any interest in using Forth whatsoever. They don't write Forth systems, they port someone else's Forth. They don't write much Forth code. It usually involves working in assembler or perhaps some high level language although usually not Forth. They take someone's C or assembler code and paste it in to their app, make some changes and they are done. Many claim this gives them a better understanding of Forth than people like Chuck.
I think if colorforth as a vital and living entity because it gets used to do things that it was designed to do. I am pleased to see that Chuck considers it to be the best Forth he has ever done in 40 years. I think there are people who enjoy using colorforth and who have no interest in porting it to a different computer.
Forth seems to mean programming applications to some and porting Forth or disecting dead Forth to others. And these groups don't seem to have much in common. And the porters don't seem interested in programming and those already programming don't need to port very often.
I saw Pentium as mostly a distraction from Chuck's interest in Forth. Chuck said that Pentium looks like an attempt to design a chip that would be impossible to program (meaning that people are forced to use C to deal with excessive complexity). But he had to take a little time off of doing Forth to bootstrap a Forth for Pentium until he could bootstrap his Forth development environment to his Forth chips. He put in a minimal amount of time mucking around with Pentium and was happy to put that behind him and focus on using colorforth to move forward towards what he saw as the future of Forth: cheap Forth chips running modern Forth code. Porting is an occasional necessity to some programmers but it is all there is to many enthusiasts.
I said that one could not understand Chuck's ideas without following the history of Forth from early versions through cmForth, ok, and machineForth to colorforth. I said that skipping the machineForth phase and focusing on the ugly Pentium details could miss most of the picture yet this is exactly what I saw.
People who have colorforth on a half dozen computers and run it every day are not the ones who tend to be interested in Pentium code and patches to get it to run on someone else's computer. People who want to port it, or people who want to disect it and study its internals to harvest a few spare parts for their toolkit don't seem to be interested in using colorforth. I prefer to think of it as a beautiful living thing rather than to think of it as pickled dead frog.
I work with a lot of people using colorforth. I trained most of them. The list is constantly increasing. I doubt if any of them, besides me, even subscribe to the colorforth mailing list. I think it appears to mostly be about porting old versions of colorforth or about Pentium expertise.
Chuck is where he said he would be, moving towards getting colorforth and okad running on the chips that okad was designed to design. He could not put the Pentium behind him fast enough. And instead of colorforth being a bridge to modern Forth many other people got stuck a decade behind in Pentium details.
My colorforth code is about 90% SEAforth colorforth code and 10% okad colorforth code and 0% Pentium code. I work at the colorforth level on Pentium or SEAforth. They are roughtly equivalent except that there is a huge difference between the colorforth abstraction level and the Pentium hardware level but an almost one to one correspondence between SEAforth colorforth abstraction level and the SEAforth hardware level. This was the idea from the beginning. And if anyone got stuck at the Pentium porting level without following up on the whole reason for colorforth in the first place I think they have the problem that their thinking will be twenty or thirty years behind the logic behind colorforth.
Pentium coding requires a massive expenditure of effort to understand Pentium, pretty much a full time job for anyone who wants to try. I have only met a few people who seem to have a very good grasp of Pentium details. I think there are fewer who understand Forth. And almost none who get both.
Colorforth users are elevated above that level and for the most part don't need to drop into Pentium assembler except to optimize any significant bottlenecks in apps. And we have seen so many times that a good optimizing compiler or hand written assembler can make your code run several times faster, but a system that lets you experiment easily may produce code that runs hundreds or thousands of times faster. And it is all about the use cycle, not the porting cycle.
I think that the people who are using colorforth have the impression that the mail list is mostly about 'porting' antique stuff and that's not what they do with colorforth. Other people were unable to run early colorforths and became interested in taking them apart and porting or studying them. And there is nothing wrong with that. But it just has nothing to do with full time users.
One learns one set of things about frogs from studying them in their natural environment or by getting a doctorate in zoology and specializing in frogs. And people who spend an hour disecting a dead frog in a pan of fermaldahide in a biology class learn something else about frogs.
It is like the difference between a chatroom of users using a product and exchaning information on how they solved problems in using it and the sorts of discussions that take place in say c.l.f where people who don't use or program in Forth post pages of opinions about 'Forth programmers' every day. Although the colorforth mail list has been pretty good regarding bandwidth devoted to opinions about colorforth and has been focused on porting details and application code.
Most Forth programmers don't bother reading what the very confused 'almost-programmers' in c.l.f say about Forth. They are in constant dialog with other people who are using Forth and for the most part none of them engage in the porting and theory discussions that take place in c.l.f.
I think users don't care much about what non-users think because it is irrelevant to them. Non-users don't care what users think because it is irrelevant to them too. These two groups can get rather hostile towards one another. Even the colorforth chatroom seems to me to be dominated by comments by people who seem to hate Forth. I found the same sort of nonsense and hate speech there that is common in c.l.f, basically Forth programmers get insulted there by non-Forth programmers or non-programmers.
So I could post a lot of colorforth code. It is code that I like and that Chuck likes, but I have the impression it doesn't interest the colorforth maillist subscribers because it isn't about Pentium ports and Pentium patches and getting an antique Forth running on some old computer. 90% of my colorforth is simple, SEAforth code.
Sound input? Great I have drivers.
Sound output? Great I have drivers.
High quality sound? Great.
Video drivers? Great.
Communication protocols? Great.
R/F input? Great I have drivers.
R/F output? No problem.
But my code is colorforth for SEAforth. That was the whole idea behind colorforth in the first place.
My PC can already do sound input and sound output and I don't need colorforth to do that. I do have an interest in sound applications and I could write them for the PC using colorforth. But I would prefer to do sound processing with something more embeddable, cheaper, and lower power, and higher performance than a mere PC. That's why colorforth exists.
So Chuck says that his small programs are a little smaller than yours, but that his big programs are a lot smaller than yours. And sure you can replace a K of code in your system with less colorforth code. But the real value of colorforth is when you can use it replace a few gigabytes of other code with a few kilobytes of colorforth source that you can control.
Chuck has been adding more and more SEAforth colorforth code and is well on his way to get colorforth on SEAforth. That's step one into getting okad on SEAforth instead of on the dreadful Pentium. This has always been Chuck's interest and the purpose of colorforth, to get away from the dreadful Pentium as fast as possible. Although that bootstrap period seems to be about 15 years. And Chuck is moving past that phase while most other people who say that they are doing Forth are in my opinion just duplicating a small fraction of small fraction of his work from 30 years ago or from 15 years ago.
I guess I feel that I could say that if it isn't solving a significant real problem in the real world it isn't really Forth. I think it is a little like Chuck saying that if it isn't a hundred times smaller than C it isn't really Forth. I might combine the two things and say that if it isn't doing something that is impossible in C it isn't Forth. Those who only live in the small area where Forth and C/Forth hybrids overlap simply can't understand that most of Forth is outside all that.
OK, IntellaSys has a couple of people who are working at the Pentium level in colorforth, adding system functions or optimizing application bottlenecks. But most users stay at the colorforth level writing cad code or SEAforth code to solve real-world problems, they program...
c.l.f is simply not an option for colorforth discussions. There is little activity in the colorforth mail list and the chat room is dreadful. Most of the activity in the mail list is about versions that are very old to people who get a new release once a month so they have little interest in what patches people have added to versions that are years old. But at work there are lots of people working fulltime in colorforth.
Meanwhile things that are different are happening with the application. In the windows environment you have access to icons and windows functions. And enchancements are possible that were not present on the original bootstrap floppy versions.
If you click on some word a window may pop-up with a video of Chuck explaining the feature in detail. And people who are working on that sort of thing don't seem to show much interst in the problems of people who can't boot an antique floppy version on an incompatible antique computer.
All in all the problems with colorforth are really no different than the problems with Forth. There are professionals who work with it full time and work with other Forth professionals full time. And they have access to a lot of information and they have very different experiences and knowledge than people who can't get colorforth to boot.
One of my favorite examples was that one notable colorforth enthusiast who had spent years studying it, disassembling it, reassembling it and modifying it, and made a lot of public comments about it, but had never bothered running it and in two years of 'study' had not been able to figure out how to do something in colorforth as simple as:
1 dup +
I have seen professional programmers with no background in Forth get training in colorforth and start delivering new impressive applications written in colorforth the next day. I have also seen people who dabbled in Forth for decades spend years working with colorforth and yet never learn to add one to one in the language.
So I don't think people who program in colorforth every day have much interest in reading what people who have not been able to boot colorforth or have but have spent years without getting as far as being able to enter a 1 number from the keyboard to the Forth command line in colorforth think about their experiences of not using colorforth, or about what colorforth has in common with their Perl or C code or antique Forth code.
And people porting colorforth seem to have little interest in what it does, how it is used, or what people using it do with it. But some spend years doing an autopsy on dead code that they don't even run.
Live frogs are just very different than dead frogs.
How does one master Forth? An interesting article by Philip E. Ross appeared in the August issue of Scientific American titled, "The Expert Mind." "Studies in the mental process of chess grandmasters have revealed clues to how people become experts in other fields as well."
In reading the article I was reminded of a lecture by Marvin Minsky on the subject of how people learn and what constitutes being an expert. I was reminded of my own decades of studies in various fields and in the words of my own teachers.
"Effortful study is the key to achieving success in chess, classical music, soccer and many other fields. New research has indicated that motivation is a more important factor than innate ability."
The common wisdom to becoming an expert in anything is 'Practice, practice, practice." But as I was often reminded by my teachers, practicing an error over and over just makes it habit. What is required in addition to motivation and effort is focus. And we should probably consider that there will likely be a contrast between the common view and the expert view.
There are examples throughout history of the giants who had to work out the first principles in new fields and upon who's shoulders following work was built. As a body of knowledge progress people can build on the knowledge derived from the work of previous masters in the field.
The practitioner of any art or any person seeking to master any field will seek out either the work of previous masters or the actual guidance and council of a master in the field they wish to study. Their own intention and motivation is directed and guided with effort to focus on the important details to be studied to make the progress requried to master any field. Most people are motivied at first and make considerable progress as beginners in a new field, but considerable effort and focus distinguishes those who achieve the mastery that few achieve in any field. Most people reach a plateu at the limit of their own unaided ability to learn in a self-directed manner or at the limit of the skill of their teacher. Students who become masters are often told by their teacher that they have outgrown the teacher and need to advance to directed study under a master with a different mastery.
What does it take to become a master? As Marvin Minsky told us so long ago and as noted in the recent Scientific American article the distinction between an expert in a field and the rest of us has been studied and quantified. We understand things in 'chunks' which are sort of like facts in a specific context of experience in problem solving. We accumualte knowledge in these chunks and when we have accumulated about 50,000 of them we are considered to be 'an expert' in a field by other humans.
"The 10-year rule states that it takes approximately a decade of heavy labor to master any field."
The great strength and weakness of Forth for those of us who did not invent it is that it seems so simple. It seems so simple that many people, like myself, reported that when I first encountered Forth I really felt that I understood almost all of it in about 3 minutes. After a decade of doing a lot of Forth and a lot of other languages I had accumuated a few years of study in Forth and considered myself an expert. I had passed some of my first teachers in my understanding of Forth but had found people who clearly knew much more than I and began my serious study of the subject.
Having had experience with the tradition of studying under Zen and martial arts masters I had much the same dedicated self-sacrificing focuses effortful study that is required to achieve the kind of results that warrant the efforts of an established master to mentor or tutor one in a field. The degree of effort required to master a field is not something that is well understood by the average person who does not have and does not want such an experience.
I had fifteen years of professional programming experience split pretty evenly between assembler, BASIC, C, Pascal, and a variety of scripting language environments. I was a successful professional in my field and accumulated an above average body of knowledge, chunks of knowledge about programming. I accumulated a few years of experience at most in each language.
In the mid eighties I became very interested in the new Forth chips that had been build by the inventor of Forth and in the new Forth software that he had written for them. I bought some, programmed them and did several projects. I designed and built a prototype Forth engine multiprocessor laptop. In the nearly twenty years that have followed I have worked almost exclusively with the Forth language using and writing Forth compilers, libraries, Operating Systems, development enviroments, simulators, emulators, cad programs, GUI, test systems, Internet protocols and Internet based applications like browser and email clients. In Forth, on Forth, under Forth, for Forth, developing and using almost exclusively Forth software and often Forth hardware.
I have also had the opportunity to study directly under the inventor of Forth, Chuck Moore, for over fifteen years and to have been guided and assisted in my study of Forth by other well known Forth professionals and masters. I began with an introduction to Forth and mostly used it as a portable monitor/debugger on new computers or with new programs or as a scripting language layer on top of some system. One can be easily lured into understanding that much Forth in fifteen minutes and thinking you have mastered the language.
When I engaged in directed study of an art from a master I found that I had to start over. It was the old parable of the teacup needing to be emptied. I was full of my own expertise and needed to be able to see with the fresh eyes of a beginner and feel that need to make the effort to change whatever needs to be changed in yourself to achieve mastry of your art.
Though traditionally a student does not 'argue' with his master, he may engage in dialog to work towards an understanding. In the case of Mr. Moore and myself I was usually defending the rational behind the ANS Forth standard effort and in the common practices at the time. I could trace what I had been taught back through my teachers and their teachers and of course back to Chuck Moore eventually in the case of Forth. And I could see how each person had added their own understanding and filtered out the parts of what other people were doing that was not compatible with what they were thinking.
I often found myself very challanged and suprised to see that I had been completely wrong about so many things that I really had though I had understood and mastered in those years when I had part time exposure to Forth. I often did not learn what I expected to learn and I observed that Mr. Moore did not always learn what he expected to learn. I observed that he was less sure of exactly what Forth was and what it could do than almost anyone else and was willing to try as many ideas as he could to find a solution while most other people had very narrow definitions for what they considered Forth.
As my teachers in martial arts had always reminded me I had to make and effort to keep 'beginner's mind' and be open to new ideas. I understood that thinking that you understand an art is usually the point where you stop learning and advancing and being just practicing your bad habits.
To a casual game player it might appear that chess and checkers and other games with a similar board have a lot in common and that skills at playing one board game should be pretty transferable to a different game. But academic research in chess, 'the Drosophila of Cognitive Science' as Mr. Ross puts it, has clearly shown that chucks of knowledge about chess are not the same as chunks of knowledge about checkers or other board games.
Programming languages have some things in common. You can write a 'hello world' program in any language. Programming language shave some things that distinguish them from one another the way checkers and chess are different. To the casual user, or a person who's expertise is limited to things like 'hello world' applications that can be written knowledge of Forth has a lot of common chunks with knowledge of other programming languages.
But you get a different view when you talk to the people who have accumulated sufficient chunks of knowledge specific to Forth, the things that distinguish it from other forms of programming, to be considered masters of Forth. These people know that like chess you have to have experience with Forth to become a master of Forth. And the rule is, it takes about ten years of doing focused effortful study in Forth to approach mastery.
If what Mr. Ross says in the Scientific American article is true the effort which must be expended in purposeful directed and focused study is more important in creating a master in a field than inate ability in the individual. Even so I might note that most the Forth programmers I know seem to be in the top two or three percent in intelligence profiles in addition to having invested a considerable effort into the mastery of Forth programming.
All of this is in sharp contrast to the modern American 'instant culture with instant gratification' where the rule seems to be that anything that is hard isn't worth doing. Forth culture is one that abhors black-boxes and hidden details and values the simplicity, clarity, and a complete understanding of hardware, software, algorithms and problems solutions. The strength of Forth has always been to many people that it is both grounded a what people call the lowest levels of simple mechanical operation and extends to whatever lofty level of abstraction is desired. And that contrasts the trend to provide an abstracted-only view of computing in which almost all the details can be hidden from users who can either be unskilled low-cost labor or can be easily controlled by computer systems that they don't understand.
There are people today who brag about spending their 2000 hours at work a year spread out evenly over administration, programming and documentation. They may brag about spreading the 700 hours a year they spend programming over as many as thirty different programming languages.
This should be amusing to Forth programmers considering the history of Forth as an escape from the 'multi-language nightmare.' How much more of a nightmare today where people have thirty different specialized programming languages putting them into a much more elaborate maze than could have been imagined fourty years ago?
I always used to tell my students that they should factor in that being human they would forget some of their training. I told them to expect to forget about one hour's worth per week. So if you put two hours a week of effort into your study you will accumulate about one hours worth a week. In a year you will accumulate about fifty hours worth of study. And research tells us that that is about a hundred chunks of expert knowledge. I often reminded my students that if you stay near the threshold of forgetting in your study that you will not make much forward progress. If you put in one hour a week you will never go beyond the beginner level. If you put in three hours a week you will make twice as much progress as if you put in two.
And of course, if you want to master the art expect to accumulate at least fifty thousand of these chunks. If you accumualte 100 a year you would need to live to be five hundred years old to master your art. Those who want to master their arts often put in a hundred hours of work a week for many years to get enough chunks to do what masters do.
Those who tell you that programming in 30 language will help you master Forth are problably aware of what Forth has in common with those 30 other languages. If they had a few hundred years they might be able to also learn what makes Forth different. But as many of those folks seem convinced that the best way to learn Forth is by using other programming languages I have my doubts that they will ever learn more than about 1% of Forth.
Not everyone wants to seek out experts who are so far beyond your skill that to them you are a rank beginner to study from them. It can be quite a humbling experience. If your teacup is full, if you are already 'a master at a glance' you will see no benefit for the sort of effortful and directed study that scientific research has shown is what makes masters.
I have always told people that some arts can be studied in a self-directed way and some can't. In most cases if you are truely serious about study you need to look for masters until you find one who you can relate to and who is willing to teach you. Then you need to suffer and bleed. I recall a dance teacher telling us that any day we didn't bleed we were wasting his time and ours.
The only way you will ever really master anything is if you spend a good part of your life at it which would be a great sacrifice were it not the thing you love. Those who like Forth because they think it is something you can learn in fifteen minutes seem to dislike the idea that some people think Forth is something that is that hard to master. Those who have made an effort to master Forth dislike the notion that Forth is just that thing you can learn in fifteen minutes.
My problem with your FAQs is the assumption that the greatest bottleneck is always that there will only be one Central Processing Unit. Parallel processing is all about not having a single "Central" Processinng Unit. Here is a clip from a fairly typical FAQ on microcontrollers on the subject of interrupts:
"The advantage of interrupts, compared with polling, is the speed of response to external events and reduced software overhead (of continually asking peripherals if they have any data ready)."
The FAQ is saying that a single Central Processing Unit can't do something simple like read a pin in a loop efficiently. It says that the real problem is that if there is only one CPU and it does more than one thing, then the delay in responding to any given event could be the sum of the time required to respone to all events. So when a loop does more than reading a pin and looping waiting to process the event it is slower than the minimal poll loop.
Interrupts require extra hardware and extra software. We used three interrupts to support use of the Forth processor by the realtime IO coprocessors on the UltraTechnology F21. When a hardware event occurs there may be a delay before the CPU can get to processing the event due to interrupts being disabled either explicity or automatically by some sequence of CPU instructions. When an interrupt happens the machine will save a minimal amount of information and be vectored to an Interrupt Service Routine. This routine will then save any other required state information. Then the routine begins to execute the code that actually does whatever service the event requires.
Take a look at any microcontroller or microprocessor and count the number of CPU cycles or memory cycles involved in all of that. On more complicated CPU it may be difficult to predict in any deterministic way how exactly many cycles it is going to take. Particular instruction sequences or those that explicity disable interrupts, cache misses or pipeline stalls caused by interrupts may require many unplanned cycles.
The common sense knowledge that everyone has, and what one reads in the microcontroller FAQs is that microcontrollers need interrupts to repsond to events quickly. I work with designs that don't have interrupts. They can have very fast poll loops. I can read a pin, test it, and loop or respond in six nanoseconds and that is with a very cheap processor. But people know that an interrupt and all that extra hardware and software would make this faster, but they are wrong.
A temporarily assigned and dedicated processor can be used to poll or to sleep and be awakened by a signal on a pin. It will be much faster, cheaper, and lower power than a single overburdened and interrupted CPU. Where one has power to program function blocks with multiprocessor synchronization down to the instruction level one is not constrained in the way the FAQs say that embedded processor designs are constrained.
There seem to be two major schools of thought on this. One uses a language that was designed to write a pre-emptive multi-tasking multi-user Operating System to run possibly ill-disposed and uncooperative programs. The other uses a language designed to avoid those typical OS problems and use cooperative hardware/software and cooperative multitasking with cooperative programs. How and why do hardware designs assist with the problems of locked, insoluble, contrary, obdurate, recalcitrant, uncooperative, or unruly software?
I recently asked a question in comp.lang.forth, "hardware errors, do C and Forth need different things in hardware?" I listed ten examples of how simple Forth language programs work in a simple and cooperative manner. I expected that some people might say that they were actually errors that needed extra hardware to correct. Is it just a case of what we see as what makes cooperative hardware and software easy being exactly why people with uncooperative software see it as a bad thing requiring extra hardware and software?
Yes, it is a lot like a Volvox Supercomputer. But instead of 2048 10mip nodes one of our prototypes has 24 1000 mip nodes. The hardware channel links are a thousand times faster, and we can use any normal external memories, and we have standard communication protocols between cluster chips, and our individual processors are about too small to see, and they consume no power when sleeping and very little when running, and it has on-chip io, and it uses some cleverness to get picosecond and nanosecond response to realtime events, and it will be used in embedded products, and it will be used in rf apps, and it will cost a lot less than a Volvox supercomputer. But other than that, it is a lot like a Volvox supercomuter in a scalable network of supercomputers.
Portable electronics are more popular and people want more battery life, and smaller size. Also heat is the big design problem on the high end. Heat comes from burning power.
Going to smaller transistors means lower voltage but higher frequencies raises power. So designers use adjustable clocks and power control circuits that shut down unused parts of a chip. Smaller transistors also typically means more transistors and more leakage current too.
AMD had a recent presentation about the problem where they showed that with overclocking they got a 20% speedup at a cost of a 70% increase in power, then they tried two cores and got a 70% speedup with a 2% increase in power. Which would customers prefer? This is why Intel, AMD, and so many other companys say the megahertz wars ended at the submicron heat wall.
PCs used something like 50 billion dollars per year worth of electricity a decade ago, and here in California the cost of electricity went up about an order of magnitude. That equates to a lot of money we have all paid up front and alot more money to pay in the future for all the polution and greenhouse gases released by the burning of hundreds of billions of dollars worth of fuels to power PC.
I built a laptop with a NOVIX and a solar panel in 88 and it would run 24/7 if it got some sun every day. The idea of F21 was that it would be ten times faster, and a hundred times cheaper and lower power so that the same cheap solar powered or hand cranked laptop could have much more computing power with more computing nodes.
F21 coprocessors could be turned off or on and the power they used depeneded on what they did and at what frequency. Outputting a white pixel took much more power than running the CPU. There was a register to control memory speeds at a given voltage, and lower voltage meant a slower clock and lower power consumption. By lowering voltage to as low as 2.6V power consumption could be kept as low as sleep mode on many processors while it polled io for events upon which to raise operating voltage to perform real processing. It was kind of a trick but it worked to manage power.
With smaller geometry we planned to add RAM and ROM and put more processors on one die to increase speed and reduce cost and power consumption. Pins are expensive and draw power. Pads that drive pins are absolutely huge compared to computing transistors! (I mean pins are expensive relative to computing circuits and cost about a cent each on an F21 package. I was not referring to how adding one more pin to the F21 design would have cost me an additional $10,000.00 on each fab.)
I find it a strange notion that pins and processors are both getting smaller and cheaper but that small processors are getting smaller and cheaper faster than the pins and could be cheaper than pins in designs before too long. It reminds me of my physics instructor saying in 1971 that microprocesssors would someday be cheaper than mechanical switches and copper wires. What is not so hard to picture is that even on the big processor side of things multi-core can reduce the power consumption problem. Pipelining and multi- threading parallelism work up to a point then have diminishing returns.
One can find countless pages on the web explaining Amdahl's law for the speedup of parallel computing compared to serial computing. Speedup is defined as the ratio of time required to do a computation serially divided by the time required to do it in parallel.
Speedup = time_serial/time_parallel
If p is the number of processors and q is the ratio of parallel code to total code then
Speedup = 1/(q/p + (1-q))
So the law says that if all the code is parallel then q is 1 and 1/(1/p +0) and speedup is p.
So it says that if code is 100% parallel then p nodes will give p speedup and that the limit in theory is linear speedup.
Examples are given where q is low, and examples where speedup is greater than p, superlinear speedup, are dismissed as cases where more cache on more nodes meant more of the problem ran in cache. Real superlinear speedup, speedup greater than p, is all about the algorithm. As more people look for parallel algorithms to take advantage of parallel hardware more people will see more superlinear speedup the flaw in Amdahl's law for parallel speedup.
April 30, 2006, What's in a name?
Intelasys becomes IntellaSys after an agreement with Intel.
I hadn't realized that Dick Pountain had been involved in the Transputer though I knew of some of his connections to Forth. Marcel Hendrix provided some interesting history of tForth with some Dhrystone benchmarks comparing the 20MHz Transputer to a 33MHz 386/387 in comp.lang.forth recently. There were some comments about the Archipel Volvox computer which had 2048 Transputer nodes. I still tell people that they should study the Transputer if they want to understand parallel ideas behind F21: boot from a network, integrated multi-tasking/multi-processing, scalability, hardware support for channels etc.
The T800 Transputer added floating point hardware , but was an order of magnitude slower than F21 on integer and drew an order of magnitude more power. The Transputer did have on-chip RAM which was nice, but external memory required expensive TRAMs while F21 could work with a wide range of ordinay $1 memory chips. The Transputer had no IO except its proprietary links while F21 had a proprietary network for links, and a video IO coprocessor, and an analog IO coprocessor, and a parallel port, and a realtime clock, and an interrupt controller etc. So one could use an F21 like a Transputer and also take advantage of built-in IO hardware to treat an F21 node more like a PC with programmable video io, programmable sound io, programmable modem io, programmable network io, and parallel io subsystems in addition to the CPU.
Chuck's Sh-Boom had been getting 80 MIPS in programmable logic before the Transputer came out so the Transputer was really quite a step down compared to the performance of even early Forth chips. I like the idea of that 2048 Transputer node Volvox computer, but I wonder how much it cost and how many kilowatts of power it needed to be able to deliver twenty thousand mips.
A google search on the Spring Microprocessor Forum in San Jose yields up lots of references to the keynote speaker, Chuck Moore, Senior Fellow at AMD, and architect of new multi-core designs. Old press releases reported that AMD licensed technology developed by a different Chuck Moore, inventor of the Forth programming language turned chip designer. That Chuck Moore, CTO at Intelasys in Cupertino, will be speaking at the Spring Microprocessor Forum about new multi-core designs. I expect that at least a few people will be confused by the presence of more Chuck Moore than they expected.
