It is widely accepted today in supercomputing that workstation farms are more economical than supercomputers. Since these networks of workstations are often already available and interconnected DSM software permits these machines to be used as supercomputers. This paper will discuss the use of DSM in parallel programming in the Forth programming language.
Multitasking in Forth
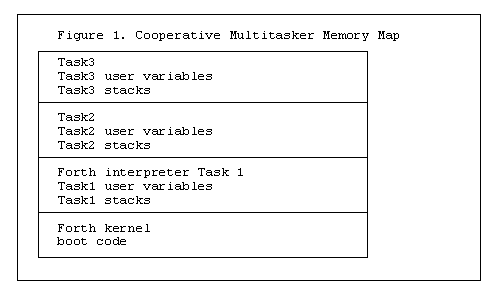
Forth does not provide a standard multitasking mechanism. Multitasking in Forth is usually either done in a simple portable co-operative scheme or using OS multitasking services. Forth is often used in embedded applications where Forth is the OS and on small computers that may have no hardware memory protection. Figure 1 shows a memory map for a typical cooperative multitasking Forth application. There is no physical memory protection to prevent one task from crashing the Forth OS. Instead each task has its own stacks and user variables but all memory is shared and available to all tasks. However each task must have a certain amount of local memory for its stacks and local user variables. In a traditional Forth multitasker the word PAUSE would switch control from one task to another which simplifies task synchronization.
In a computer that provides memory protection in hardware the OS used often provides services to limit the memory that a program or task may access. Any access to memory through protected memory hardware, or through memory access services from an OS can provide error traps for attempts to access protected memory. Certain tasks and programs may be able to run with access to only one section of memory but many others will need a certain amount of memory be available to more than one program or task. Figure 2 is an example of a protected mode operating system running three tasks that are physically separate in memory except for a small area of shared memory used for data only.
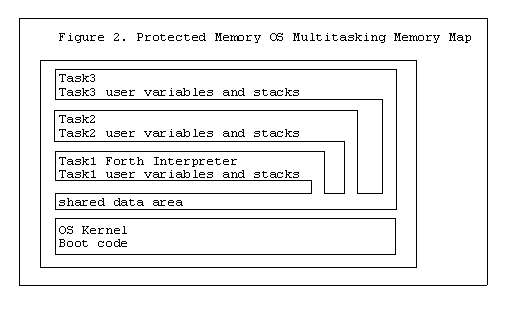
In the protected mode OS example the shared memory is logically separated using memory protection hardware or OS services. Often only a small amount of memory need be global or shared. This is a form of parallelism as tasks may logically execute in parallel even though they are still physically time-sharing the CPU. In the case task2 and task3 are copies of the same task just operating on different data they could share the same memory for code, but would still require a local (protected) memory for stacks and user variables.
Coupled Multiprocessors
Multiprocessors do not really have ``central'' processors, instead they have multiple processors. The processors on these machines can be tightly coupled or loosely coupled. Tightly coupled machines use memory that is physically shared so that part or all of the memory available to a processor is also available to other processors. Figure 3 shows a multiprocessor with four processors and a shared memory.
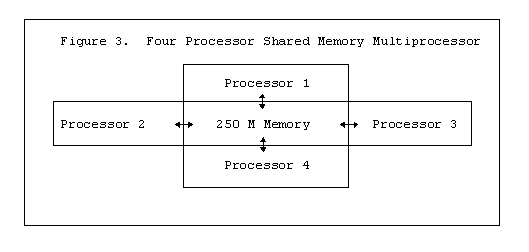
The advantage of the tightly coupled design is that memory is physically shared so access may be very fast and in the example in Figure 3 all of the memory is available to each processor. In the case of the Cray II the memory interface there are four sections of memory that may be accessed simultaneously. So only when processors access a region that another processor is using will bus arbitration be needed. The disadvantages of the tightly couple design are the high cost and the physical constraints on the hardware interconnect at the memory access level.
In Figure 1 most memory is shared and each task has some local memory. In figure 2 each task has a separate memory space, but some memory is shared for global variables. In Figure 3 each processor can have its own memory space, and shared memory is available to all processors. In Figure 4 a system with a networked ring of 4 computers is show with the memory physically distributed across the four machines.
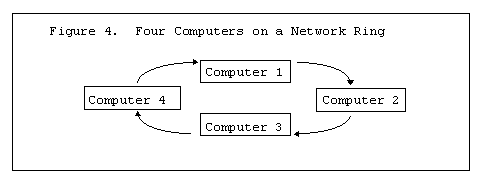
The arrow indicates a network interconnect between machines. In this case a ring is depicted, but other topologies are possible. The memory in each of the machines are physically separate, but shared memory can easily be simulated in software using the network. The Distributed Shared Memory or DSM is just a portion of memory on each machine that is identical on all machines. Physically the memory on these machines is separate, but logically it can be shared. To be DSM it must be written to via an OS service. This service will actually update all of the memories on the computers on the network so that all machines have their own copy of this global shared memory. This portion of memory that is declared global is duplicated on each machine on the network. Since there is a local copy of this memory on each machine there is no need to access the network to read from this memory. However writes to this memory must be performed via an OS service that guarantees atomic access to this memory.
Forth - Linda
Forth-Linda provided a ``Linda'' extension to the Forth Language. Linda provides access to a ``tuple'' space which is a form of DSM. In Linda global data is written to and read from the DSM in passive tuples. These tuples have neither a name nor an address but are access by a description of the tuple. In Linda programs are executed remotely on other machines via active tuples.
Forth-Linda was much simpler than conventional Linda implementations for several reasons. Forth-Linda was intended for homogeneous environments, while Linda is actually designed for the more general purpose heterogeneous computing environments. Forth-Linda was also intended for a single network protocol as well. Thus Forth-Linda was really intended for the simpler case of symmetric- multiprocessing.
Forth-Linda was implemented on a simulated multiprocessor using multitasking, and experiments were done on a Novell network. Forth-Linda only needed five operations:

Parallel Channels
Dr. Michael Montvelishsky published a parallel programming
extension to Forth based on a combination of Forth-Linda and
OCCAM. This wordset takes advantage of the concept of
synchronizing multiprocessing execution through data
channels as in OCCAM.
Dr. Montvelishsky kept the active tuple concept from Forth-Linda,
but replaced the
cumbersome passive tuples for data exchange with parallel
channels. The parallel channel wordset was published in FD
in 1994 in a fairly portable form, and has been optimized
for several Forth systems.
F*F
F*F is the name of the Forth Parallel programming extension that has evolved from Forth-Linda. F*F is even simpler than Forth-Linda because passive tuples have been replaced with an atomic network global store. The implementation of F*F requires the extension of network services to provide a remote program execution queue similar to Forth-Linda but simpler this is RX( string ). Access to the DSM is provided by G!. G! acts like a normal Forth ! in that it writes data to an address, but G! must write to the distributed memory of all of the machines on the network. In fact there will be provision for declaring a sub-set of machines on the network to be a group, and for broadcasting directly to this group of machines with a single transmission. The use of G! rather than passive tuples also simplifies the implementation. F*F is also a simpler and easier to use programming environment than Forth-Linda. The minimal number of operations needed to extend Forth to a parallel programming language has been reduced from 5 to 2. F*F will also include network tools and Dr. Montvelishsky's parallel channel wordset.
Ultra Technology is considering an implementation of F*F under a portable Forth in C and using TCP/IP across the internet to deliver supercomputing power to certain applications.
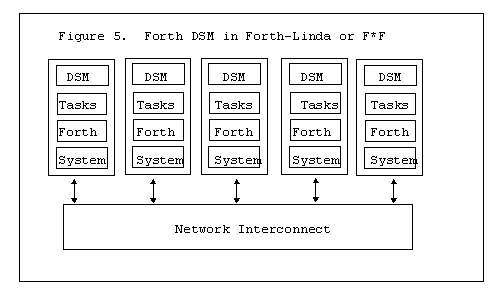
In Forth-Linda or F*F one of the machines on a network runs as a master and manages the queue of tasks and passive tuples or global memory writes. Then many machines on this network run identical copies of F*F. This is show in Figure 5.
F21 DSM Hardware
Ultra Technology is developing an inexpensive high- performance microprocessor called the F21. F21 will demonstrate that minimal hardware is needed to implement the network interface upon which DSM may be built. The network interface on F21 will provide two hardware services. A CPU interrupt or a DMA transfer may be sent to a machine or a group of machines on the F21 ring. The serial-network interface on F21 will only require a few transistors to implement, will add only a few cents to the cost of the chip, and should perform one to two orders of magnitude faster than eithernet. F*F will be very simple to implement on F21 as most of the function of RX( ) and G! will be performed by hardware. Figure 6 is a function diagram of the F21 chip.
Figure 6. Functional diagram of F21
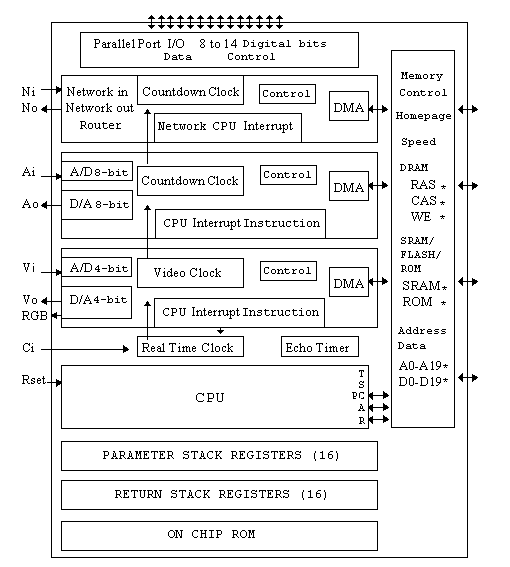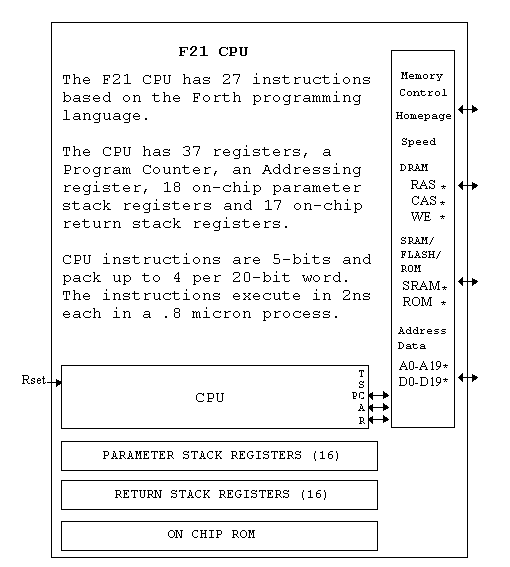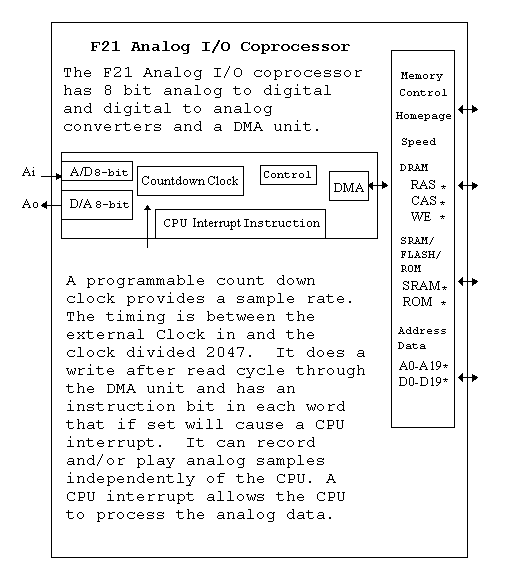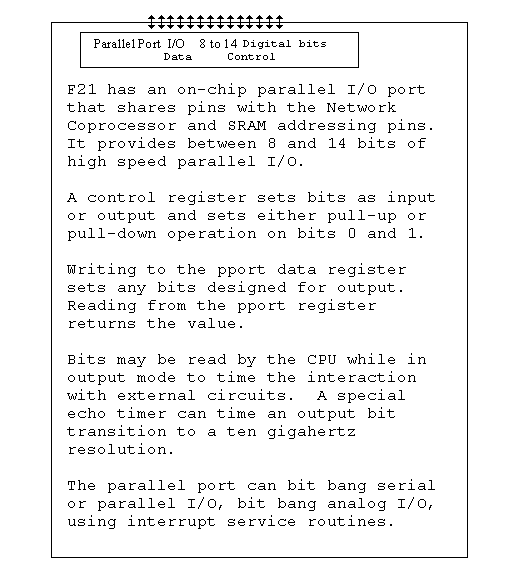
F21 Status
F21 is still being designed by Charles Moore the inventor of Forth. Ultra Technology plans to prototype F21 in .8 micron CMOS VLSI technology at MOSIS in February of 1995. Volume production should follow later in the year.